Estimating effect of multiple treatments#
[1]:
import dowhy
dowhy.enable_notebook_rendering()
from dowhy import CausalModel
import dowhy.datasets
import warnings
warnings.filterwarnings('ignore')
[2]:
data = dowhy.datasets.linear_dataset(10, num_common_causes=4, num_samples=10000,
num_instruments=0, num_effect_modifiers=2,
num_treatments=2,
treatment_is_binary=False,
num_discrete_common_causes=2,
num_discrete_effect_modifiers=0,
one_hot_encode=False)
df=data['df']
df.head()
[2]:
| X0 | X1 | W0 | W1 | W2 | W3 | v0 | v1 | y | |
|---|---|---|---|---|---|---|---|---|---|
| 0 | -0.913387 | 1.350759 | -1.741192 | -1.197867 | 3 | 2 | 6.281050 | 8.143206 | 415.956375 |
| 1 | -0.627155 | 2.262886 | -0.941252 | -0.021577 | 1 | 3 | 3.836674 | 8.691055 | 494.893179 |
| 2 | -1.366484 | 0.777586 | -2.617007 | 0.358667 | 3 | 1 | 0.848869 | 3.912431 | 46.309863 |
| 3 | -0.735154 | -0.160323 | -1.723268 | -0.726777 | 1 | 0 | -0.537654 | -2.018717 | -36.205988 |
| 4 | -0.466044 | -0.428775 | 0.198858 | 1.204649 | 0 | 3 | 6.158671 | 10.895653 | -44.393282 |
[3]:
model = CausalModel(data=data["df"],
treatment=data["treatment_name"], outcome=data["outcome_name"],
graph=data["gml_graph"])
[4]:
model.view_model()
from IPython.display import Image, display
display(Image(filename="causal_model.png"))
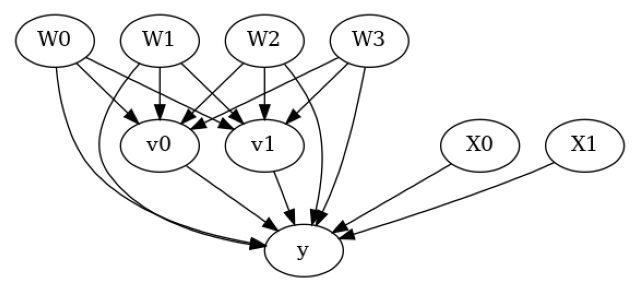
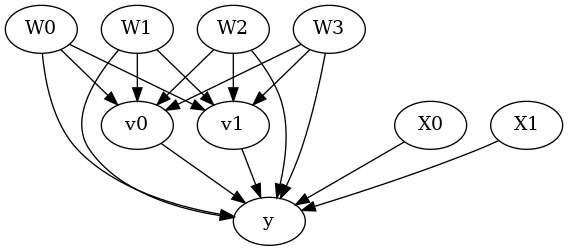
[5]:
identified_estimand= model.identify_effect(proceed_when_unidentifiable=True)
print(identified_estimand)
Estimand type: EstimandType.NONPARAMETRIC_ATE
### Estimand : 1
Estimand name: backdoor
Estimand expression:
d
─────────(E[y|W1,W2,W0,W3])
d[v₀ v₁]
Estimand assumption 1, Unconfoundedness: If U→{v0,v1} and U→y then P(y|v0,v1,W1,W2,W0,W3,U) = P(y|v0,v1,W1,W2,W0,W3)
### Estimand : 2
Estimand name: iv
No such variable(s) found!
### Estimand : 3
Estimand name: frontdoor
No such variable(s) found!
Linear model#
Let us first see an example for a linear model. The control_value and treatment_value can be provided as a tuple/list when the treatment is multi-dimensional.
The interpretation is change in y when v0 and v1 are changed from (0,0) to (1,1).
[6]:
linear_estimate = model.estimate_effect(identified_estimand,
method_name="backdoor.linear_regression",
control_value=(0,0),
treatment_value=(1,1),
method_params={'need_conditional_estimates': False})
print(linear_estimate)
*** Causal Estimate ***
## Identified estimand
Estimand type: EstimandType.NONPARAMETRIC_ATE
### Estimand : 1
Estimand name: backdoor
Estimand expression:
d
─────────(E[y|W1,W2,W0,W3])
d[v₀ v₁]
Estimand assumption 1, Unconfoundedness: If U→{v0,v1} and U→y then P(y|v0,v1,W1,W2,W0,W3,U) = P(y|v0,v1,W1,W2,W0,W3)
## Realized estimand
b: y~v0+v1+W1+W2+W0+W3+v0*X1+v0*X0+v1*X1+v1*X0
Target units: ate
## Estimate
Mean value: 35.41641181173637
You can estimate conditional effects, based on effect modifiers.
[7]:
linear_estimate = model.estimate_effect(identified_estimand,
method_name="backdoor.linear_regression",
control_value=(0,0),
treatment_value=(1,1))
print(linear_estimate)
*** Causal Estimate ***
## Identified estimand
Estimand type: EstimandType.NONPARAMETRIC_ATE
### Estimand : 1
Estimand name: backdoor
Estimand expression:
d
─────────(E[y|W1,W2,W0,W3])
d[v₀ v₁]
Estimand assumption 1, Unconfoundedness: If U→{v0,v1} and U→y then P(y|v0,v1,W1,W2,W0,W3,U) = P(y|v0,v1,W1,W2,W0,W3)
## Realized estimand
b: y~v0+v1+W1+W2+W0+W3+v0*X1+v0*X0+v1*X1+v1*X0
Target units:
## Estimate
Mean value: 35.41641181173637
### Conditional Estimates
__categorical__X1 __categorical__X0
(-3.846, -0.617] (-3.542, -0.882] -95.322032
(-0.882, -0.305] -73.417985
(-0.305, 0.218] -56.003902
(0.218, 0.798] -41.784637
(0.798, 3.663] -15.013376
(-0.617, -0.00412] (-3.542, -0.882] -37.667395
(-0.882, -0.305] -14.898568
(-0.305, 0.218] 0.154082
(0.218, 0.798] 15.500249
(0.798, 3.663] 38.931031
(-0.00412, 0.512] (-3.542, -0.882] -2.252417
(-0.882, -0.305] 20.823320
(-0.305, 0.218] 35.235357
(0.218, 0.798] 49.615928
(0.798, 3.663] 73.363719
(0.512, 1.1] (-3.542, -0.882] 32.694632
(-0.882, -0.305] 55.084251
(-0.305, 0.218] 70.247163
(0.218, 0.798] 85.253466
(0.798, 3.663] 110.031058
(1.1, 3.878] (-3.542, -0.882] 88.590825
(-0.882, -0.305] 113.278576
(-0.305, 0.218] 125.425530
(0.218, 0.798] 141.243135
(0.798, 3.663] 166.348320
dtype: float64
More methods#
You can also use methods from EconML or CausalML libraries that support multiple treatments. You can look at examples from the conditional effect notebook: https://py-why.github.io/dowhy/example_notebooks/dowhy-conditional-treatment-effects.html
Propensity-based methods do not support multiple treatments currently.