Demo for the DoWhy causal API#
We show a simple example of adding a causal extension to any dataframe.
[1]:
import dowhy
dowhy.enable_notebook_rendering()
import dowhy.datasets
import dowhy.api
from dowhy.graph import build_graph_from_str
import numpy as np
import pandas as pd
from statsmodels.api import OLS
[2]:
data = dowhy.datasets.linear_dataset(beta=5,
num_common_causes=1,
num_instruments = 0,
num_samples=1000,
treatment_is_binary=True)
df = data['df']
df['y'] = df['y'] + np.random.normal(size=len(df)) # Adding noise to data. Without noise, the variance in Y|X, Z is zero, and mcmc fails.
nx_graph = build_graph_from_str(data["dot_graph"])
treatment= data["treatment_name"][0]
outcome = data["outcome_name"][0]
common_cause = data["common_causes_names"][0]
df
[2]:
| W0 | v0 | y | |
|---|---|---|---|
| 0 | 1.946486 | True | 9.601481 |
| 1 | 0.830639 | False | 1.848806 |
| 2 | -0.146411 | True | 6.541884 |
| 3 | 1.111248 | True | 6.600895 |
| 4 | -0.059885 | True | 3.016531 |
| ... | ... | ... | ... |
| 995 | 0.091708 | True | 4.413204 |
| 996 | 0.632677 | True | 4.706617 |
| 997 | 0.437943 | True | 5.230384 |
| 998 | 2.558886 | True | 9.743775 |
| 999 | 1.665350 | True | 8.772056 |
1000 rows × 3 columns
[3]:
# data['df'] is just a regular pandas.DataFrame
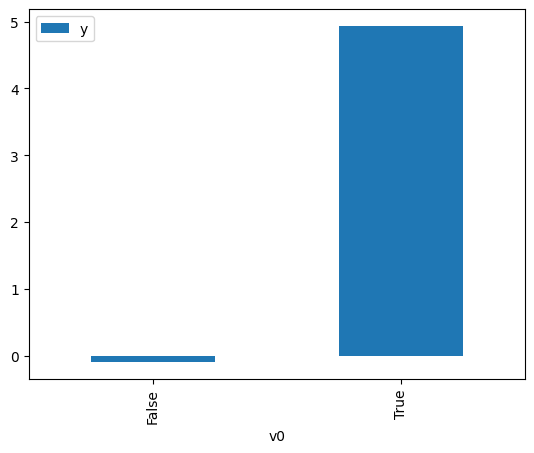
df.causal.do(x=treatment,
variable_types={treatment: 'b', outcome: 'c', common_cause: 'c'},
outcome=outcome,
common_causes=[common_cause],
).groupby(treatment).mean().plot(y=outcome, kind='bar')
[3]:
<Axes: xlabel='v0'>
[4]:
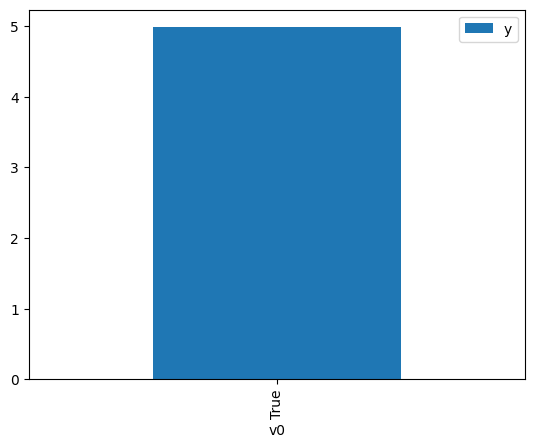
df.causal.do(x={treatment: 1},
variable_types={treatment:'b', outcome: 'c', common_cause: 'c'},
outcome=outcome,
method='weighting',
common_causes=[common_cause]
).groupby(treatment).mean().plot(y=outcome, kind='bar')
[4]:
<Axes: xlabel='v0'>
[5]:
cdf_1 = df.causal.do(x={treatment: 1},
variable_types={treatment: 'b', outcome: 'c', common_cause: 'c'},
outcome=outcome,
graph=nx_graph
)
cdf_0 = df.causal.do(x={treatment: 0},
variable_types={treatment: 'b', outcome: 'c', common_cause: 'c'},
outcome=outcome,
graph=nx_graph
)
[6]:
cdf_0
[6]:
| W0 | v0 | y | propensity_score | weight | |
|---|---|---|---|---|---|
| 0 | 0.397159 | False | 0.659022 | 0.369388 | 2.707182 |
| 1 | 2.229516 | False | 4.665517 | 0.046024 | 21.727891 |
| 2 | 0.463989 | False | 1.447101 | 0.348441 | 2.869930 |
| 3 | 1.154969 | False | 1.776468 | 0.172590 | 5.794071 |
| 4 | -0.686871 | False | -2.221900 | 0.719539 | 1.389778 |
| ... | ... | ... | ... | ... | ... |
| 995 | 0.651798 | False | 0.020120 | 0.292806 | 3.415234 |
| 996 | 1.505612 | False | 1.669227 | 0.114544 | 8.730250 |
| 997 | -1.652279 | False | -3.144685 | 0.905302 | 1.104604 |
| 998 | 0.374365 | False | 1.510566 | 0.376651 | 2.654976 |
| 999 | 1.025267 | False | 1.324563 | 0.199303 | 5.017491 |
1000 rows × 5 columns
[7]:
cdf_1
[7]:
| W0 | v0 | y | propensity_score | weight | |
|---|---|---|---|---|---|
| 0 | 0.007914 | True | 5.214271 | 0.501122 | 1.995523 |
| 1 | 1.886673 | True | 8.859618 | 0.928531 | 1.076969 |
| 2 | 0.988608 | True | 6.329401 | 0.792606 | 1.261660 |
| 3 | 0.801659 | True | 6.300524 | 0.747625 | 1.337569 |
| 4 | 0.382875 | True | 6.355585 | 0.626067 | 1.597273 |
| ... | ... | ... | ... | ... | ... |
| 995 | 1.167872 | True | 6.102895 | 0.829906 | 1.204956 |
| 996 | 1.473154 | True | 7.980661 | 0.880893 | 1.135211 |
| 997 | 0.553763 | True | 6.335199 | 0.678791 | 1.473208 |
| 998 | 0.259339 | True | 6.149736 | 0.585905 | 1.706763 |
| 999 | 1.017072 | True | 6.894531 | 0.798909 | 1.251707 |
1000 rows × 5 columns
Comparing the estimate to Linear Regression#
First, estimating the effect using the causal data frame, and the 95% confidence interval.
[8]:
(cdf_1['y'] - cdf_0['y']).mean()
[8]:
$\displaystyle 5.13983696214543$
[9]:
1.96*(cdf_1['y'] - cdf_0['y']).std() / np.sqrt(len(df))
[9]:
$\displaystyle 0.172382321522194$
Comparing to the estimate from OLS.
[10]:
model = OLS(np.asarray(df[outcome]), np.asarray(df[[common_cause, treatment]], dtype=np.float64))
result = model.fit()
result.summary()
[10]:
| Dep. Variable: | y | R-squared (uncentered): | 0.976 |
|---|---|---|---|
| Model: | OLS | Adj. R-squared (uncentered): | 0.976 |
| Method: | Least Squares | F-statistic: | 2.047e+04 |
| Date: | Sun, 19 Jul 2026 | Prob (F-statistic): | 0.00 |
| Time: | 05:31:53 | Log-Likelihood: | -1370.0 |
| No. Observations: | 1000 | AIC: | 2744. |
| Df Residuals: | 998 | BIC: | 2754. |
| Df Model: | 2 | ||
| Covariance Type: | nonrobust |
| coef | std err | t | P>|t| | [0.025 | 0.975] | |
|---|---|---|---|---|---|---|
| x1 | 1.8546 | 0.035 | 53.162 | 0.000 | 1.786 | 1.923 |
| x2 | 4.9893 | 0.053 | 93.914 | 0.000 | 4.885 | 5.094 |
| Omnibus: | 2.229 | Durbin-Watson: | 1.924 |
|---|---|---|---|
| Prob(Omnibus): | 0.328 | Jarque-Bera (JB): | 2.284 |
| Skew: | 0.112 | Prob(JB): | 0.319 |
| Kurtosis: | 2.933 | Cond. No. | 2.85 |
Notes:
[1] R² is computed without centering (uncentered) since the model does not contain a constant.
[2] Standard Errors assume that the covariance matrix of the errors is correctly specified.