DoWhy: Different estimation methods for causal inference#
This is a quick introduction to the DoWhy causal inference library. We will load in a sample dataset and use different methods for estimating the causal effect of a (pre-specified)treatment variable on a (pre-specified) outcome variable.
We will see that not all estimators return the correct effect for this dataset.
First, let us add the required path for Python to find the DoWhy code and load all required packages
[1]:
%load_ext autoreload
%autoreload 2
[2]:
import numpy as np
import pandas as pd
import logging
import dowhy
dowhy.enable_notebook_rendering()
from dowhy import CausalModel
import dowhy.datasets
Now, let us load a dataset. For simplicity, we simulate a dataset with linear relationships between common causes and treatment, and common causes and outcome.
Beta is the true causal effect.
[3]:
data = dowhy.datasets.linear_dataset(beta=10,
num_common_causes=5,
num_instruments = 2,
num_treatments=1,
num_samples=10000,
treatment_is_binary=True,
outcome_is_binary=False,
stddev_treatment_noise=10)
df = data["df"]
df
[3]:
| Z0 | Z1 | W0 | W1 | W2 | W3 | W4 | v0 | y | |
|---|---|---|---|---|---|---|---|---|---|
| 0 | 1.0 | 0.771007 | 0.792523 | 0.197928 | -0.522803 | 0.371499 | -0.943244 | True | 7.782218 |
| 1 | 0.0 | 0.892036 | 0.522133 | 1.266979 | 0.041113 | 1.693183 | -0.553175 | True | 15.805774 |
| 2 | 0.0 | 0.584357 | -0.561473 | -0.913393 | 0.254559 | -0.633652 | 1.400382 | True | 11.796090 |
| 3 | 1.0 | 0.143307 | -1.159718 | -0.735834 | 2.151812 | 1.685511 | -0.756638 | True | 19.896334 |
| 4 | 1.0 | 0.372807 | 0.238936 | -0.010809 | -0.677877 | -2.428901 | -0.276429 | False | -11.383229 |
| ... | ... | ... | ... | ... | ... | ... | ... | ... | ... |
| 9995 | 1.0 | 0.501876 | -0.296596 | -0.015990 | 1.446301 | -0.590175 | -1.022582 | False | 0.784815 |
| 9996 | 0.0 | 0.112633 | 0.988676 | -0.284725 | 0.209223 | 0.975156 | -1.237735 | True | 12.456467 |
| 9997 | 0.0 | 0.481378 | -0.564809 | 0.372093 | -1.652111 | -0.002740 | -2.315747 | False | -16.304851 |
| 9998 | 1.0 | 0.368566 | 0.144519 | 0.617793 | -0.585166 | 0.728797 | -1.158700 | True | 6.597773 |
| 9999 | 1.0 | 0.376153 | 1.714476 | -0.684502 | -1.274787 | 1.118163 | 0.041069 | True | 11.711187 |
10000 rows × 9 columns
Note that we are using a pandas dataframe to load the data.
Identifying the causal estimand#
We now input a causal graph in the DOT graph format.
[4]:
# With graph
model=CausalModel(
data = df,
treatment=data["treatment_name"],
outcome=data["outcome_name"],
graph=data["gml_graph"],
instruments=data["instrument_names"]
)
[5]:
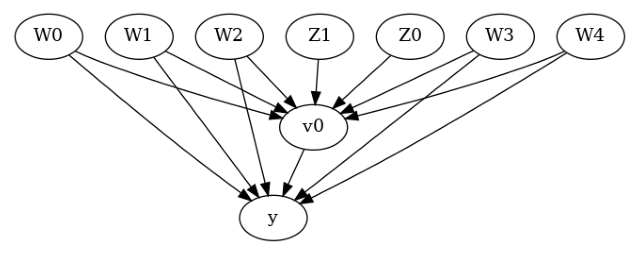
model.view_model()
[6]:
from IPython.display import Image, display
display(Image(filename="causal_model.png"))
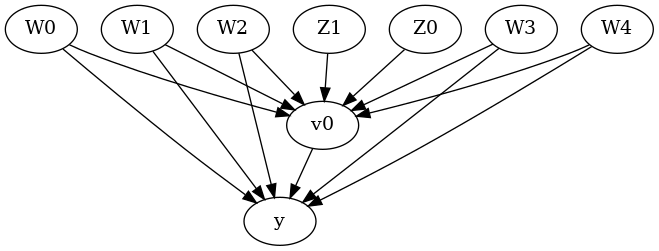
We get a causal graph. Now identification and estimation is done.
[7]:
identified_estimand = model.identify_effect(proceed_when_unidentifiable=True)
print(identified_estimand)
Estimand type: EstimandType.NONPARAMETRIC_ATE
### Estimand : 1
Estimand name: backdoor
Estimand expression:
d
─────(E[y|W0,W4,W2,W1,W3])
d[v₀]
Estimand assumption 1, Unconfoundedness: If U→{v0} and U→y then P(y|v0,W0,W4,W2,W1,W3,U) = P(y|v0,W0,W4,W2,W1,W3)
### Estimand : 2
Estimand name: iv
Estimand expression:
⎡ -1⎤
⎢ d ⎛ d ⎞ ⎥
E⎢─────────(y)⋅⎜─────────([v₀])⎟ ⎥
⎣d[Z₁ Z₀] ⎝d[Z₁ Z₀] ⎠ ⎦
Estimand assumption 1, As-if-random: If U→→y then ¬(U →→{Z1,Z0})
Estimand assumption 2, Exclusion: If we remove {Z1,Z0}→{v0}, then ¬({Z1,Z0}→y)
### Estimand : 3
Estimand name: frontdoor
No such variable(s) found!
Method 1: Regression#
Use linear regression.
[8]:
causal_estimate_reg = model.estimate_effect(identified_estimand,
method_name="backdoor.linear_regression",
test_significance=True)
print(causal_estimate_reg)
print("Causal Estimate is " + str(causal_estimate_reg.value))
*** Causal Estimate ***
## Identified estimand
Estimand type: EstimandType.NONPARAMETRIC_ATE
### Estimand : 1
Estimand name: backdoor
Estimand expression:
d
─────(E[y|W0,W4,W2,W1,W3])
d[v₀]
Estimand assumption 1, Unconfoundedness: If U→{v0} and U→y then P(y|v0,W0,W4,W2,W1,W3,U) = P(y|v0,W0,W4,W2,W1,W3)
## Realized estimand
b: y~v0+W0+W4+W2+W1+W3
Target units: ate
## Estimate
Mean value: 10.000459857808634
p-value: 0 (significant at alpha=0.05; H0: treatment has no causal effect on outcome)
Causal Estimate is 10.000459857808634
Method 2: Distance Matching#
Define a distance metric and then use the metric to match closest points between treatment and control.
[9]:
causal_estimate_dmatch = model.estimate_effect(identified_estimand,
method_name="backdoor.distance_matching",
target_units="att",
method_params={'distance_metric':"minkowski", 'p':2})
print(causal_estimate_dmatch)
print("Causal Estimate is " + str(causal_estimate_dmatch.value))
/home/runner/.cache/pypoetry/virtualenvs/dowhy-n6DJFijf-py3.9/lib/python3.9/site-packages/sklearn/neighbors/_unsupervised.py:179: SyntaxWarning: Parameter p is found in metric_params. The corresponding parameter from __init__ is ignored.
return self._fit(X)
*** Causal Estimate ***
## Identified estimand
Estimand type: EstimandType.NONPARAMETRIC_ATE
### Estimand : 1
Estimand name: backdoor
Estimand expression:
d
─────(E[y|W0,W4,W2,W1,W3])
d[v₀]
Estimand assumption 1, Unconfoundedness: If U→{v0} and U→y then P(y|v0,W0,W4,W2,W1,W3,U) = P(y|v0,W0,W4,W2,W1,W3)
## Realized estimand
b: y~v0+W0+W4+W2+W1+W3
Target units: att
## Estimate
Mean value: 10.835592464803689
Causal Estimate is 10.835592464803689
Method 3: Propensity Score Stratification#
We will be using propensity scores to stratify units in the data.
[10]:
causal_estimate_strat = model.estimate_effect(identified_estimand,
method_name="backdoor.propensity_score_stratification",
target_units="att")
print(causal_estimate_strat)
print("Causal Estimate is " + str(causal_estimate_strat.value))
*** Causal Estimate ***
## Identified estimand
Estimand type: EstimandType.NONPARAMETRIC_ATE
### Estimand : 1
Estimand name: backdoor
Estimand expression:
d
─────(E[y|W0,W4,W2,W1,W3])
d[v₀]
Estimand assumption 1, Unconfoundedness: If U→{v0} and U→y then P(y|v0,W0,W4,W2,W1,W3,U) = P(y|v0,W0,W4,W2,W1,W3)
## Realized estimand
b: y~v0+W0+W4+W2+W1+W3
Target units: att
## Estimate
Mean value: 10.053600991800977
Causal Estimate is 10.053600991800977
Method 4: Propensity Score Matching#
We will be using propensity scores to match units in the data.
[11]:
causal_estimate_match = model.estimate_effect(identified_estimand,
method_name="backdoor.propensity_score_matching",
target_units="atc")
print(causal_estimate_match)
print("Causal Estimate is " + str(causal_estimate_match.value))
*** Causal Estimate ***
## Identified estimand
Estimand type: EstimandType.NONPARAMETRIC_ATE
### Estimand : 1
Estimand name: backdoor
Estimand expression:
d
─────(E[y|W0,W4,W2,W1,W3])
d[v₀]
Estimand assumption 1, Unconfoundedness: If U→{v0} and U→y then P(y|v0,W0,W4,W2,W1,W3,U) = P(y|v0,W0,W4,W2,W1,W3)
## Realized estimand
b: y~v0+W0+W4+W2+W1+W3
Target units: atc
## Estimate
Mean value: 10.013241899194174
Causal Estimate is 10.013241899194174
Method 5: Weighting#
We will be using (inverse) propensity scores to assign weights to units in the data. DoWhy supports a few different weighting schemes:
Vanilla Inverse Propensity Score weighting (IPS) (weighting_scheme=”ips_weight”)
Self-normalized IPS weighting (also known as the Hajek estimator) (weighting_scheme=”ips_normalized_weight”)
Stabilized IPS weighting (weighting_scheme = “ips_stabilized_weight”)
[12]:
causal_estimate_ipw = model.estimate_effect(identified_estimand,
method_name="backdoor.propensity_score_weighting",
target_units = "ate",
method_params={"weighting_scheme":"ips_weight"})
print(causal_estimate_ipw)
print("Causal Estimate is " + str(causal_estimate_ipw.value))
*** Causal Estimate ***
## Identified estimand
Estimand type: EstimandType.NONPARAMETRIC_ATE
### Estimand : 1
Estimand name: backdoor
Estimand expression:
d
─────(E[y|W0,W4,W2,W1,W3])
d[v₀]
Estimand assumption 1, Unconfoundedness: If U→{v0} and U→y then P(y|v0,W0,W4,W2,W1,W3,U) = P(y|v0,W0,W4,W2,W1,W3)
## Realized estimand
b: y~v0+W0+W4+W2+W1+W3
Target units: ate
## Estimate
Mean value: 11.220285478838127
Causal Estimate is 11.220285478838127
Method 6: Instrumental Variable#
We will be using the Wald estimator for the provided instrumental variable.
[13]:
causal_estimate_iv = model.estimate_effect(identified_estimand,
method_name="iv.instrumental_variable", method_params = {'iv_instrument_name': 'Z0'})
print(causal_estimate_iv)
print("Causal Estimate is " + str(causal_estimate_iv.value))
*** Causal Estimate ***
## Identified estimand
Estimand type: EstimandType.NONPARAMETRIC_ATE
### Estimand : 1
Estimand name: iv
Estimand expression:
⎡ -1⎤
⎢ d ⎛ d ⎞ ⎥
E⎢─────────(y)⋅⎜─────────([v₀])⎟ ⎥
⎣d[Z₁ Z₀] ⎝d[Z₁ Z₀] ⎠ ⎦
Estimand assumption 1, As-if-random: If U→→y then ¬(U →→{Z1,Z0})
Estimand assumption 2, Exclusion: If we remove {Z1,Z0}→{v0}, then ¬({Z1,Z0}→y)
## Realized estimand
Realized estimand: Wald Estimator
Realized estimand type: EstimandType.NONPARAMETRIC_ATE
Estimand expression:
⎡ d ⎤
E⎢───(y)⎥
⎣dZ₀ ⎦
──────────
⎡ d ⎤
E⎢───(v₀)⎥
⎣dZ₀ ⎦
Estimand assumption 1, As-if-random: If U→→y then ¬(U →→{Z1,Z0})
Estimand assumption 2, Exclusion: If we remove {Z1,Z0}→{v0}, then ¬({Z1,Z0}→y)
Estimand assumption 3, treatment_effect_homogeneity: Each unit's treatment ['v0'] is affected in the same way by common causes of ['v0'] and ['y']
Estimand assumption 4, outcome_effect_homogeneity: Each unit's outcome ['y'] is affected in the same way by common causes of ['v0'] and ['y']
Target units: ate
## Estimate
Mean value: 9.698535217147729
Causal Estimate is 9.698535217147729
Method 7: Regression Discontinuity#
We will be internally converting this to an equivalent instrumental variables problem.
[14]:
causal_estimate_regdist = model.estimate_effect(identified_estimand,
method_name="iv.regression_discontinuity",
method_params={'rd_variable_name':'Z1',
'rd_threshold_value':0.5,
'rd_bandwidth': 0.15})
print(causal_estimate_regdist)
print("Causal Estimate is " + str(causal_estimate_regdist.value))
*** Causal Estimate ***
## Identified estimand
Estimand type: EstimandType.NONPARAMETRIC_ATE
### Estimand : 1
Estimand name: iv
Estimand expression:
⎡ -1⎤
⎢ d ⎛ d ⎞ ⎥
E⎢─────────(y)⋅⎜─────────([v₀])⎟ ⎥
⎣d[Z₁ Z₀] ⎝d[Z₁ Z₀] ⎠ ⎦
Estimand assumption 1, As-if-random: If U→→y then ¬(U →→{Z1,Z0})
Estimand assumption 2, Exclusion: If we remove {Z1,Z0}→{v0}, then ¬({Z1,Z0}→y)
## Realized estimand
Realized estimand: Wald Estimator
Realized estimand type: EstimandType.NONPARAMETRIC_ATE
Estimand expression:
⎡ d ⎤
E⎢──────────────────(y)⎥
⎣dlocal_rd_variable ⎦
─────────────────────────
⎡ d ⎤
E⎢──────────────────(v₀)⎥
⎣dlocal_rd_variable ⎦
Estimand assumption 1, As-if-random: If U→→y then ¬(U →→{Z1,Z0})
Estimand assumption 2, Exclusion: If we remove {Z1,Z0}→{v0}, then ¬({Z1,Z0}→y)
Estimand assumption 3, treatment_effect_homogeneity: Each unit's treatment ['v0'] is affected in the same way by common causes of ['v0'] and ['y']
Estimand assumption 4, outcome_effect_homogeneity: Each unit's outcome ['y'] is affected in the same way by common causes of ['v0'] and ['y']
Target units: ate
## Estimate
Mean value: 0.08269152172884993
Causal Estimate is 0.08269152172884993
Method 8: Doubly Robust Estimator#
Combines a regression estimator and a propensity score estimator to give back a doubly robust estimate.
[15]:
causal_estimate_doubly_robust = model.estimate_effect(identified_estimand,
method_name="backdoor.doubly_robust",
method_params={'propensity_score_column':'propensity_score_dr'}
)
print(causal_estimate_doubly_robust)
print("Causal Estimate is " + str(causal_estimate_doubly_robust.value))
*** Causal Estimate ***
## Identified estimand
Estimand type: EstimandType.NONPARAMETRIC_ATE
### Estimand : 1
Estimand name: backdoor
Estimand expression:
d
─────(E[y|W0,W4,W2,W1,W3])
d[v₀]
Estimand assumption 1, Unconfoundedness: If U→{v0} and U→y then P(y|v0,W0,W4,W2,W1,W3,U) = P(y|v0,W0,W4,W2,W1,W3)
## Realized estimand
b: y~v0+W0+W4+W2+W1+W3
Target units: ate
## Estimate
Mean value: 10.000739903877271
Causal Estimate is 10.000739903877271
Method 9: Tab-PFN Estimator#
Note: This example uses 10,000 samples thus requires a GPU. For a CPU-compatible walkthrough with smaller datasets, see dowhy_tabpfn_estimator.ipynb.
[16]:
# causal_estimate_tabpfn = model.estimate_effect(identified_estimand,
# method_name="backdoor.tabpfn",
# method_params={
# "n_estimators": 8,
# "model_type": "auto",
# "max_num_classes": 10,
# "use_multi_gpu": False,
# },
# )
# print(causal_estimate_tabpfn)
# print("Causal Estimate is " + str(causal_estimate_tabpfn.value))
[ ]: