Estimating the effect of a Member Rewards program
An example on how DoWhy can be used to estimate the effect of a subscription or a rewards program for customers.
Suppose that a website has a membership rewards program where customers receive additional benefits if they sign up. How do we know if the program is effective? Here the relevant causal question is: > What is the impact of offering the membership rewards program on total sales?
And the equivalent counterfactual question is, > If the current members had not signed up for the program, how much less would they have spent on the website?
In formal language, we are interested in the Average Treatment Effect on the Treated (ATT).
I. Formulating the causal model
Suppose that the rewards program was introduced in January 2019. The outcome variable is the total spends at the end of the year. We have data on all monthly transactions of every user and on the time of signup for those who chose to signup for the rewards program. Here’s what the data looks like.
[1]:
# Creating some simulated data for our example
import pandas as pd
import numpy as np
num_users = 10000
num_months = 12
signup_months = np.random.choice(np.arange(1, num_months), num_users) * np.random.randint(0,2, size=num_users) # signup_months == 0 means customer did not sign up
df = pd.DataFrame({
'user_id': np.repeat(np.arange(num_users), num_months),
'signup_month': np.repeat(signup_months, num_months), # signup month == 0 means customer did not sign up
'month': np.tile(np.arange(1, num_months+1), num_users), # months are from 1 to 12
'spend': np.random.poisson(500, num_users*num_months) #np.random.beta(a=2, b=5, size=num_users * num_months)*1000 # centered at 500
})
# A customer is in the treatment group if and only if they signed up
df["treatment"] = df["signup_month"]>0
# Simulating an effect of month (monotonically decreasing--customers buy less later in the year)
df["spend"] = df["spend"] - df["month"]*10
# Simulating a simple treatment effect of 100
after_signup = (df["signup_month"] < df["month"]) & (df["treatment"])
df.loc[after_signup,"spend"] = df[after_signup]["spend"] + 100
df
[1]:
| user_id | signup_month | month | spend | treatment | |
|---|---|---|---|---|---|
| 0 | 0 | 6 | 1 | 507 | True |
| 1 | 0 | 6 | 2 | 506 | True |
| 2 | 0 | 6 | 3 | 490 | True |
| 3 | 0 | 6 | 4 | 464 | True |
| 4 | 0 | 6 | 5 | 475 | True |
| ... | ... | ... | ... | ... | ... |
| 119995 | 9999 | 0 | 8 | 396 | False |
| 119996 | 9999 | 0 | 9 | 387 | False |
| 119997 | 9999 | 0 | 10 | 367 | False |
| 119998 | 9999 | 0 | 11 | 436 | False |
| 119999 | 9999 | 0 | 12 | 358 | False |
120000 rows × 5 columns
The importance of time
Time plays a crucial role in modeling this problem.
Rewards signup can affect the future transactions, but not those that happened before it. In fact, the transactions prior to the rewards signup can be assumed to cause the rewards signup decision. Therefore we split up the variables for each user:
Activity prior to the treatment (assumed a cause of the treatment)
Activity after the treatment (is the outcome of applying treatment)
Of course, many important variables that affect signup and total spend are missing (e.g., the type of products bought, length of a user’s account, geography, etc.). This is a critical assumption in the analysis, one that needs to be tested later using refutation tests.
Below is the causal graph for a user who signed up in month i=3. The analysis will be similar for any i.
[2]:
import dowhy
# Setting the signup month (for ease of analysis)
i = 3
[3]:
causal_graph = """digraph {
treatment[label="Program Signup in month i"];
pre_spends;
post_spends;
Z->treatment;
pre_spends -> treatment;
treatment->post_spends;
signup_month->post_spends;
signup_month->treatment;
}"""
# Post-process the data based on the graph and the month of the treatment (signup)
# For each customer, determine their average monthly spend before and after month i
df_i_signupmonth = (
df[df.signup_month.isin([0, i])]
.groupby(["user_id", "signup_month", "treatment"])
.apply(
lambda x: pd.Series(
{
"pre_spends": x.loc[x.month < i, "spend"].mean(),
"post_spends": x.loc[x.month > i, "spend"].mean(),
}
)
)
.reset_index()
)
print(df_i_signupmonth)
model = dowhy.CausalModel(data=df_i_signupmonth,
graph=causal_graph.replace("\n", " "),
treatment="treatment",
outcome="post_spends")
model.view_model()
from IPython.display import Image, display
display(Image(filename="causal_model.png"))
user_id signup_month treatment pre_spends post_spends
0 1 0 False 462.0 420.444444
1 3 0 False 518.5 415.444444
2 8 0 False 477.5 430.555556
3 11 0 False 491.5 424.666667
4 13 0 False 477.0 411.555556
... ... ... ... ... ...
5459 9992 0 False 495.0 408.777778
5460 9995 0 False 541.0 407.000000
5461 9997 0 False 472.5 412.111111
5462 9998 0 False 458.0 422.555556
5463 9999 0 False 490.5 399.666667
[5464 rows x 5 columns]
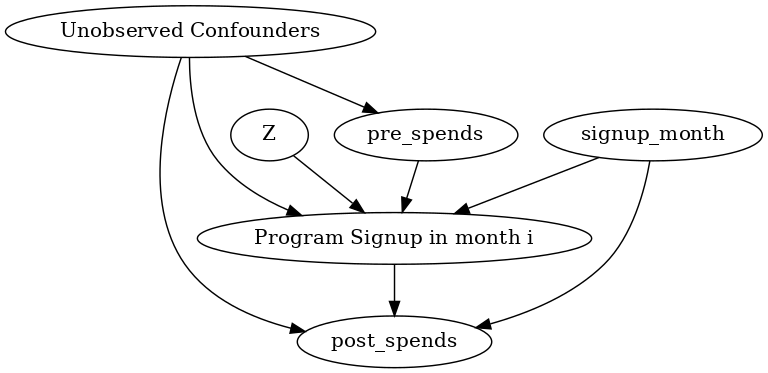
More generally, we can include any activity data for the customer in the above graph. All prior- and post-activity data will occupy the same place (and have the same edges) as the Amount spent node (prior and post respectively).
II. Identifying the causal effect
For the sake of this example, let us assume that unobserved confounding does not play a big part.
[4]:
identified_estimand = model.identify_effect(proceed_when_unidentifiable=True)
print(identified_estimand)
Estimand type: nonparametric-ate
### Estimand : 1
Estimand name: backdoor
Estimand expression:
d
────────────(Expectation(post_spends|pre_spends,signup_month))
d[treatment]
Estimand assumption 1, Unconfoundedness: If U→{treatment} and U→post_spends then P(post_spends|treatment,pre_spends,signup_month,U) = P(post_spends|treatment,pre_spends,signup_month)
### Estimand : 2
Estimand name: iv
Estimand expression:
Expectation(Derivative(post_spends, [Z])*Derivative([treatment], [Z])**(-1))
Estimand assumption 1, As-if-random: If U→→post_spends then ¬(U →→{Z})
Estimand assumption 2, Exclusion: If we remove {Z}→{treatment}, then ¬({Z}→post_spends)
### Estimand : 3
Estimand name: frontdoor
No such variable found!
Based on the graph, DoWhy determines that the signup month and amount spent in the pre-treatment months (signup_month, pre_spend) needs to be conditioned on.
III. Estimating the effect
We now estimate the effect based on the backdoor estimand, setting the target units to “att”.
[5]:
estimate = model.estimate_effect(identified_estimand,
method_name="backdoor.propensity_score_matching",
target_units="att")
print(estimate)
/home/amit/py-envs/env3.8/lib/python3.8/site-packages/sklearn/utils/validation.py:72: DataConversionWarning: A column-vector y was passed when a 1d array was expected. Please change the shape of y to (n_samples, ), for example using ravel().
return f(**kwargs)
*** Causal Estimate ***
## Identified estimand
Estimand type: nonparametric-ate
### Estimand : 1
Estimand name: backdoor
Estimand expression:
d
────────────(Expectation(post_spends|pre_spends,signup_month))
d[treatment]
Estimand assumption 1, Unconfoundedness: If U→{treatment} and U→post_spends then P(post_spends|treatment,pre_spends,signup_month,U) = P(post_spends|treatment,pre_spends,signup_month)
## Realized estimand
b: post_spends~treatment+pre_spends+signup_month
Target units: att
## Estimate
Mean value: 100.03963044006804
The analysis tells us the Average Treatment Effect on the Treated (ATT). That is, the average effect on total spend for the customers that signed up for the Rewards Program in month i=3 (compared to the case where they had not signed up). We can similarly calculate the effects for customers who signed up in any other month by changing the value of i(line 2 above) and then rerunning the analysis.
Note that the estimation suffers from left and right-censoring. 1. Left-censoring: If a customer signs up in the first month, we do not have enough transaction history to match them to similar customers who did not sign up (and thus apply the backdoor identified estimand). 2. Right-censoring: If a customer signs up in the last month, we do not enough future (post-treatment) transactions to estimate the outcome after signup.
Thus, even if the effect of signup was the same across all months, the estimated effects may be different by month of signup, due to lack of data (and thus high variance in estimated pre-treatment or post-treatment transactions activity).
IV. Refuting the estimate
We refute the estimate using the placebo treatment refuter. This refuter substitutes the treatment by an independent random variable and checks whether our estimate now goes to zero (it should!).
[6]:
refutation = model.refute_estimate(identified_estimand, estimate, method_name="placebo_treatment_refuter",
placebo_type="permute", num_simulations=20)
print(refutation)
/home/amit/py-envs/env3.8/lib/python3.8/site-packages/sklearn/utils/validation.py:72: DataConversionWarning: A column-vector y was passed when a 1d array was expected. Please change the shape of y to (n_samples, ), for example using ravel().
return f(**kwargs)
/home/amit/py-envs/env3.8/lib/python3.8/site-packages/sklearn/utils/validation.py:72: DataConversionWarning: A column-vector y was passed when a 1d array was expected. Please change the shape of y to (n_samples, ), for example using ravel().
return f(**kwargs)
/home/amit/py-envs/env3.8/lib/python3.8/site-packages/sklearn/utils/validation.py:72: DataConversionWarning: A column-vector y was passed when a 1d array was expected. Please change the shape of y to (n_samples, ), for example using ravel().
return f(**kwargs)
/home/amit/py-envs/env3.8/lib/python3.8/site-packages/sklearn/utils/validation.py:72: DataConversionWarning: A column-vector y was passed when a 1d array was expected. Please change the shape of y to (n_samples, ), for example using ravel().
return f(**kwargs)
/home/amit/py-envs/env3.8/lib/python3.8/site-packages/sklearn/utils/validation.py:72: DataConversionWarning: A column-vector y was passed when a 1d array was expected. Please change the shape of y to (n_samples, ), for example using ravel().
return f(**kwargs)
/home/amit/py-envs/env3.8/lib/python3.8/site-packages/sklearn/utils/validation.py:72: DataConversionWarning: A column-vector y was passed when a 1d array was expected. Please change the shape of y to (n_samples, ), for example using ravel().
return f(**kwargs)
/home/amit/py-envs/env3.8/lib/python3.8/site-packages/sklearn/utils/validation.py:72: DataConversionWarning: A column-vector y was passed when a 1d array was expected. Please change the shape of y to (n_samples, ), for example using ravel().
return f(**kwargs)
/home/amit/py-envs/env3.8/lib/python3.8/site-packages/sklearn/utils/validation.py:72: DataConversionWarning: A column-vector y was passed when a 1d array was expected. Please change the shape of y to (n_samples, ), for example using ravel().
return f(**kwargs)
/home/amit/py-envs/env3.8/lib/python3.8/site-packages/sklearn/utils/validation.py:72: DataConversionWarning: A column-vector y was passed when a 1d array was expected. Please change the shape of y to (n_samples, ), for example using ravel().
return f(**kwargs)
/home/amit/py-envs/env3.8/lib/python3.8/site-packages/sklearn/utils/validation.py:72: DataConversionWarning: A column-vector y was passed when a 1d array was expected. Please change the shape of y to (n_samples, ), for example using ravel().
return f(**kwargs)
/home/amit/py-envs/env3.8/lib/python3.8/site-packages/sklearn/utils/validation.py:72: DataConversionWarning: A column-vector y was passed when a 1d array was expected. Please change the shape of y to (n_samples, ), for example using ravel().
return f(**kwargs)
/home/amit/py-envs/env3.8/lib/python3.8/site-packages/sklearn/utils/validation.py:72: DataConversionWarning: A column-vector y was passed when a 1d array was expected. Please change the shape of y to (n_samples, ), for example using ravel().
return f(**kwargs)
/home/amit/py-envs/env3.8/lib/python3.8/site-packages/sklearn/utils/validation.py:72: DataConversionWarning: A column-vector y was passed when a 1d array was expected. Please change the shape of y to (n_samples, ), for example using ravel().
return f(**kwargs)
/home/amit/py-envs/env3.8/lib/python3.8/site-packages/sklearn/utils/validation.py:72: DataConversionWarning: A column-vector y was passed when a 1d array was expected. Please change the shape of y to (n_samples, ), for example using ravel().
return f(**kwargs)
/home/amit/py-envs/env3.8/lib/python3.8/site-packages/sklearn/utils/validation.py:72: DataConversionWarning: A column-vector y was passed when a 1d array was expected. Please change the shape of y to (n_samples, ), for example using ravel().
return f(**kwargs)
/home/amit/py-envs/env3.8/lib/python3.8/site-packages/sklearn/utils/validation.py:72: DataConversionWarning: A column-vector y was passed when a 1d array was expected. Please change the shape of y to (n_samples, ), for example using ravel().
return f(**kwargs)
/home/amit/py-envs/env3.8/lib/python3.8/site-packages/sklearn/utils/validation.py:72: DataConversionWarning: A column-vector y was passed when a 1d array was expected. Please change the shape of y to (n_samples, ), for example using ravel().
return f(**kwargs)
/home/amit/py-envs/env3.8/lib/python3.8/site-packages/sklearn/utils/validation.py:72: DataConversionWarning: A column-vector y was passed when a 1d array was expected. Please change the shape of y to (n_samples, ), for example using ravel().
return f(**kwargs)
/home/amit/py-envs/env3.8/lib/python3.8/site-packages/sklearn/utils/validation.py:72: DataConversionWarning: A column-vector y was passed when a 1d array was expected. Please change the shape of y to (n_samples, ), for example using ravel().
return f(**kwargs)
/home/amit/py-envs/env3.8/lib/python3.8/site-packages/sklearn/utils/validation.py:72: DataConversionWarning: A column-vector y was passed when a 1d array was expected. Please change the shape of y to (n_samples, ), for example using ravel().
return f(**kwargs)
Refute: Use a Placebo Treatment
Estimated effect:100.03963044006804
New effect:0.6054947726720156
p value:0.24154316295878647