Estimating intrinsic causal influences in real-world examples
This notebook demonstrates the usage of the intrinsic causal influence (ICC) method, a way to estimate causal influence in a system. A common question in many applications is: “What is the causal influence of node X on node Y?” Here, “causal influence” can be defined in various ways. One approach could be to measure the interventional influence, which asks, “How much does node Y change if I intervene on node X?” or, from a more feature relevance perspective, “How relevant is X in describing Y?”
In the following we focus on a particular type of causal influence, which is based on decomposing the generating process into mechanisms in place at each node, formalized by the respective causal mechanism. Then, ICC quantifies for each node the amount of uncertainty of the target that can be traced back to the respective mechanism. Hence, nodes that are deterministically computed from their parents obtain zero contribution. This concept may initially seem complex, but it is based on a simple idea:
Consider a chain of nodes: X -> Y -> Z. Y is more informative about Z than X, as Y directly determines Z and also incorporates all information from X. It is obvious that when intervening on either X or Y, Y has a more significant impact on Z. But, what if Y is just a rescaled copy of X, i.e., \(Y = a \cdot X\)? In this case, Y still has the largest interventional influence on Z, but it is not adding any new information on top of X. The ICC method, on the other hand, would attribute 0 influence to Y as it only passes on what it inherits from X.
The idea behind ICC is not to estimate the contribution of observed upstream nodes to the target node, but instead to attribute the influence of their noise terms. Since we model each node as a functional causal model of the form \(X_i = f_i(PA_i, N_i)\), we aim to estimate the contribution of the \(N_i\) terms to the target. In the previous example, we have deterministic relationships with zero noise, i.e., the intrinsic influence is 0. This type of attribution is only possible when we explicitly model our causal relationships using functional causal models, as we do in the GCM module.
In the following, we will look at two real-world examples where we apply ICC.
Intrinsic influence on car MPG consumption
In the first example, we use the famous MPG data set, which contains different features that are used for the prediction of miles per gallon (mpg) of a car engine. Let’s say our task is to improve the design process where we need a good understanding of the influences of our variables on the mpg consumption. The relationship between these features can be modeled as a graphical causal model. For this, we follow the causal graph defined in the work by Wang et al. and remove all nodes that have no influence on MPG. This leaves us with the following graph:
[1]:
import pandas as pd
import networkx as nx
import numpy as np
from dowhy import gcm
from dowhy.utils.plotting import plot, bar_plot
# Load Auto MPG data: Quinlan,R.. (1993). Auto MPG. UCI Machine Learning Repository. https://doi.org/10.24432/C5859H.
auto_mpg_data = pd.read_csv('http://archive.ics.uci.edu/ml/machine-learning-databases/auto-mpg/auto-mpg.data-original',
delim_whitespace=True,
header=None,
names = ['mpg',
'cylinders',
'displacement',
'horsepower',
'weight',
'acceleration',
'model year',
'origin',
'car name'])
auto_mpg_data.dropna(inplace=True)
auto_mpg_data.drop(['model year', 'origin', 'car name'], axis=1, inplace=True)
mpg_graph = nx.DiGraph([('cylinders', 'displacement'),
('cylinders', 'displacement'),
('displacement', 'weight'),
('displacement', 'horsepower'),
('weight', 'mpg'),
('horsepower', 'mpg')])
plot(mpg_graph)
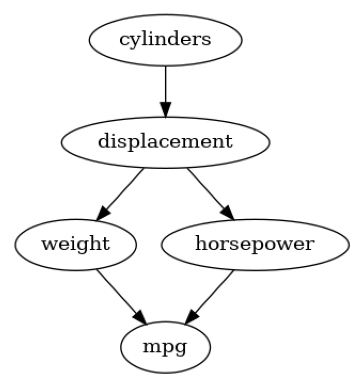
Seeing this graph, we can expect some strong confounders between the nodes, but nevertheless, we will see that the ICC method still provides non-trivial insights.
Let’s define the corresponding structural causal model and fit it to the data:
[2]:
scm_mpg = gcm.StructuralCausalModel(mpg_graph)
gcm.auto.assign_causal_mechanisms(scm_mpg, auto_mpg_data)
gcm.fit(scm_mpg, auto_mpg_data)
Fitting causal mechanism of node mpg: 100%|██████████| 5/5 [00:00<00:00, 22.86it/s]
Optionally, we can get some insights into the performance of the causal mechanisms by using the evaluation method:
[3]:
print(gcm.evaluate_causal_model(scm_mpg, auto_mpg_data, evaluate_invertibility_assumptions=False, evaluate_causal_structure=False))
Evaluating causal mechanisms...: 100%|██████████| 5/5 [00:00<00:00, 4882.78it/s]
Evaluated the performance of the causal mechanisms and the overall average KL divergence between generated and observed distribution. The results are as follows:
==== Evaluation of Causal Mechanisms ====
The used evaluation metrics are:
- KL divergence (only for root-nodes): Evaluates the divergence between the generated and the observed distribution.
- Mean Squared Error (MSE): Evaluates the average squared differences between the observed values and the conditional expectation of the causal mechanisms.
- Normalized MSE (NMSE): The MSE normalized by the standard deviation for better comparison.
- R2 coefficient: Indicates how much variance is explained by the conditional expectations of the mechanisms. Note, however, that this can be misleading for nonlinear relationships.
- F1 score (only for categorical non-root nodes): The harmonic mean of the precision and recall indicating the goodness of the underlying classifier model.
- (normalized) Continuous Ranked Probability Score (CRPS): The CRPS generalizes the Mean Absolute Percentage Error to probabilistic predictions. This gives insights into the accuracy and calibration of the causal mechanisms.
NOTE: Every metric focuses on different aspects and they might not consistently indicate a good or bad performance.
We will mostly utilize the CRPS for comparing and interpreting the performance of the mechanisms, since this captures the most important properties for the causal model.
--- Node cylinders
- The KL divergence between generated and observed distribution is 1.4679724636073446.
The estimated KL divergence indicates some mismatches between the distributions.
--- Node displacement
- The MSE is 1048.8065929207066.
- The NMSE is 0.30783192835900197.
- The R2 coefficient is 0.9039952944052189.
- The normalized CRPS is 0.17259810770001277.
The estimated CRPS indicates a very good model performance.
--- Node weight
- The MSE is 77959.90597208698.
- The NMSE is 0.3316928945352509.
- The R2 coefficient is 0.888990529547393.
- The normalized CRPS is 0.18336496635667676.
The estimated CRPS indicates a very good model performance.
--- Node horsepower
- The MSE is 228.7998701720221.
- The NMSE is 0.4065712990454805.
- The R2 coefficient is 0.8276348928508732.
- The normalized CRPS is 0.21734451953077238.
The estimated CRPS indicates a good model performance.
--- Node mpg
- The MSE is 15.5740369966684.
- The NMSE is 0.5071981947949944.
- The R2 coefficient is 0.7425924552661186.
- The normalized CRPS is 0.2804650522716592.
The estimated CRPS indicates a good model performance.
==== Evaluation of Generated Distribution ====
The overall average KL divergence between the generated and observed distribution is 0.965705159423503
The estimated KL divergence indicates a good representation of the data distribution, but might indicate some smaller mismatches between the distributions.
==== NOTE ====
Always double check the made model assumptions with respect to the graph structure and choice of causal mechanisms.
All these evaluations give some insight into the goodness of the causal model, but should not be overinterpreted, since some causal relationships can be intrinsically hard to model. Furthermore, many algorithms are fairly robust against misspecifications or poor performances of causal mechanisms.
After defining our structural causal model, we can now obtain more insights into what factors influence fuel consumption. As a first insight, we can estimate the direct arrow strength of the connections weight -> mpg and horsepower -> mpg. Note that by default, the arrow strength method measures the influence with respect to the variance.
[4]:
arrow_strengths_mpg = gcm.arrow_strength(scm_mpg, target_node='mpg')
gcm.util.plot(scm_mpg.graph, causal_strengths=arrow_strengths_mpg)
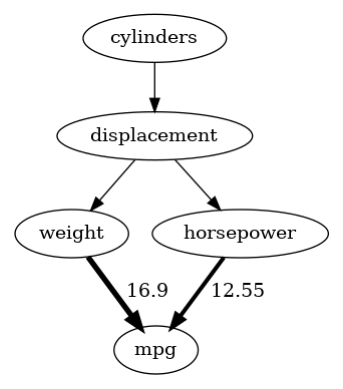
As we see here, the weight has a much higher influence on the variance in mpg than horsepower does.
While knowing how much the direct parents influence our node of interest provides some valuable insights, the weight and horsepower might only just inherit information from their common parent. To distinguish between the information inherited from the parent and their own contribution, we apply the ICC method:
[5]:
iccs_mpg = gcm.intrinsic_causal_influence(scm_mpg, target_node='mpg')
Evaluate set function: 32it [01:58, 3.72s/it]
For a better interpretation of the results, we convert the variance attribution to percentages by normalizing it over the total sum.
[6]:
def convert_to_percentage(value_dictionary):
total_absolute_sum = np.sum([abs(v) for v in value_dictionary.values()])
return {k: abs(v) / total_absolute_sum * 100 for k, v in value_dictionary.items()}
[7]:
bar_plot(convert_to_percentage(iccs_mpg), ylabel='Variance contribution in %')
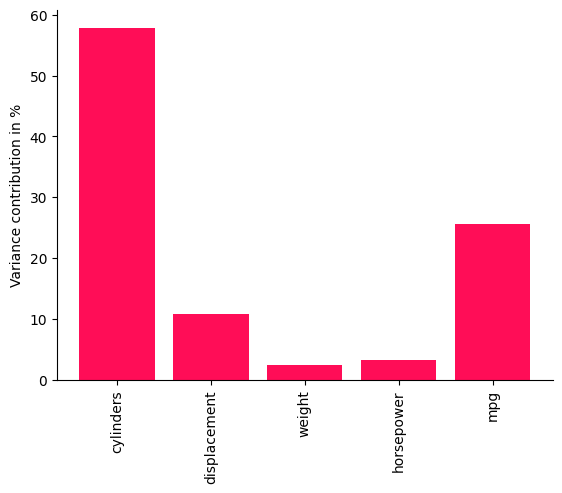
It turns out that the number of cylinders already explains a large fraction of the fuel consumption and the intermediate nodes like displacement, horsepower, and weight mostly inherit uncertainty from their parents. This is because, although weight and horsepower are the more direct predictors of mpg, they are mostly determined by displacement and cylinders. This gives some useful insights for potential optimizations. As we also see with the contribution of mpg itself, roughly 1/4 of the variance of mpg remains unexplained by all of the above factors, which may be partially due to model inaccuracies.
While the model evaluation showed that there are some inaccuracies with respect to the KL divergence between the generated and observed distributions, we see that ICC still provides non-trivial results in the sense that the contributions differ significantly across nodes and that not everything is simply attributed to the target node itself.
Note that estimating the contribution to the variance of the target in ICC can be seen as a nonlinear version of ANOVA that incorporates the causal structure.
Intrinsic influence on river flow
In the next example, we look at different recordings taken of the river flows (\(m^3/s\)) at a 15 minute frequency across 5 different measuring stations in England at Henthorn, New Jumbles Rock, Hodder Place, Whalley Weir and Samlesbury. Here, obtaining a better understanding of how the river flows behave can help to plan potential mitigation steps to avoid overflows. The data is taken from the UK Department for Environment Food & Rural Affairs website. Here is a map of the rivers:
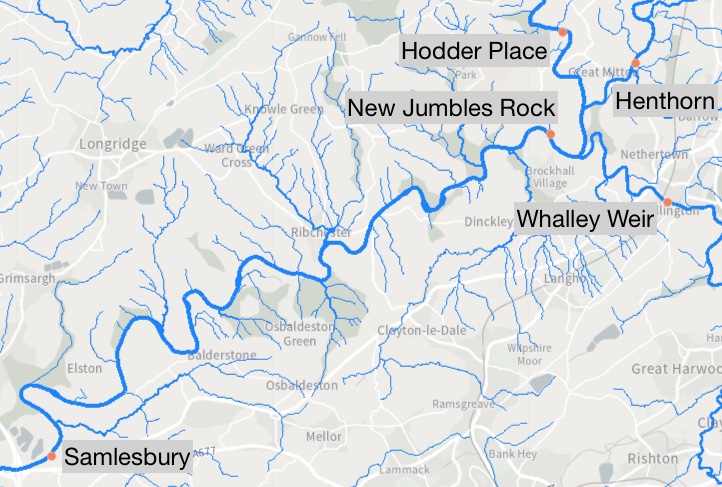
New Jumbles Rock lies at a confluence point of the 3 rivers passing Henthorn, Hodder Place, and Whalley Weir and New Jumbles Rock flows into Samlesbury. The water passing a certain measuring station is certainly a mixture of some fraction of the amount observed at the next stations further upstream plus some amount contributed by streams and little rivers entering the river in between. This defines our causal graph as:
[8]:
river_graph = nx.DiGraph([('Henthorn', 'New Jumbles Rock'),
('Hodder Place', 'New Jumbles Rock'),
('Whalley Weir', 'New Jumbles Rock'),
('New Jumbles Rock', 'Samlesbury')])
plot(river_graph)
In this setting, we are interested in the causal influence of the upstream rivers on the Samlesbury river. Similar to the example before, we would expect these nodes to be heavily confounded by, e.g., the weather. That is, the true graph is more likely to be along the lines of:
Nevertheless, we still expect the ICC algorithm to provide some insights into the contribution to the river flow of Samlesbury, even with the hidden confounder in place:
[9]:
river_data = pd.read_csv("river.csv", index_col=False)
scm_river = gcm.StructuralCausalModel(river_graph)
gcm.auto.assign_causal_mechanisms(scm_river, river_data)
gcm.fit(scm_river, river_data)
iccs_river = gcm.intrinsic_causal_influence(scm_river, target_node='Samlesbury')
bar_plot(convert_to_percentage(iccs_river), ylabel='Variance contribution in %')
Fitting causal mechanism of node Samlesbury: 100%|██████████| 5/5 [00:00<00:00, 147.95it/s]
Evaluate set function: 32it [00:00, 56.38it/s]
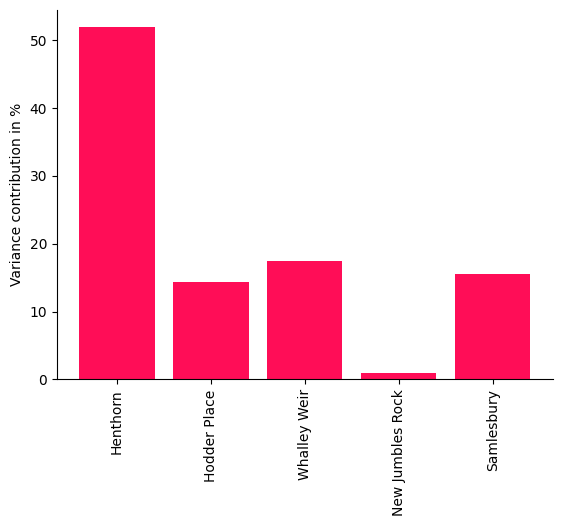
Interestingly, the intrinsic contribution of New Jumbles Rock on Samlesbury is small, although the interventional effect on New Jumbles Rock would certaintly have a large effect. This illustrates that ICC does not measure influence in the sense of the strength of a treatment effect and points out here that New Jumbles Rock simply passes the flow onto Samlesbury. The contribution by Samlesbury itself represents the (hidden) factors that are not captured. Even though we can expect the nodes to be heavily confounded by the weather, the analysis still provides some interesting insights which we only obtain by carefully distinguishing between influences that were just inherited from the parents and ‘information’ that is newly added by the node.