Falsification of User-Given Directed Acyclic Graphs
This notebook demonstrates a tool on falsifying a user-given DAG using observational data. The main function is falsify_graph(), which takes as input a DAG and data and returns an evaluation result. For more details about this method, please read the related paper:
Eulig, E., Mastakouri, A. A., Blöbaum, P., Hardt, M., & Janzing, D. (2023). Toward Falsifying Causal Graphs Using a Permutation-Based Test. https://arxiv.org/abs/2305.09565
[1]:
# Import the necessary libraries and functions for this demo
import numpy as np
import pandas as pd
import networkx as nx
from sklearn.ensemble import GradientBoostingRegressor
from dowhy.gcm.falsify import FalsifyConst, falsify_graph, plot_local_insights, run_validations, apply_suggestions
from dowhy.gcm.independence_test.generalised_cov_measure import generalised_cov_based
from dowhy.gcm.util import plot
from dowhy.gcm.util.general import set_random_seed
from dowhy.gcm.ml import SklearnRegressionModel
# Set random seed
set_random_seed(1332)
Synthetic Data
We will first demonstrate the tool on synthetic data. To this end we generated a random DAG with 5 nodes falsify_g_true.gml and some data from a random SCM with nonlinear conditionals (falsify_data_nonlinear.csv).
[2]:
# Load example graph and data
g_true = nx.read_gml(f"falsify_g_true.gml")
data = pd.read_csv(f"falsify_data_nonlinear.csv")
# Plot true DAG
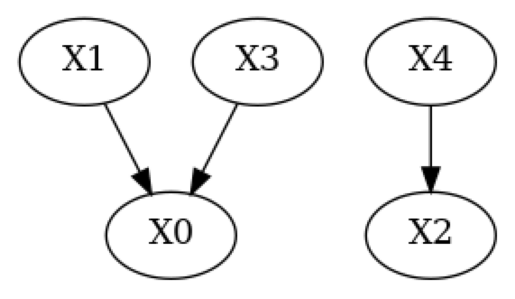
print("True DAG")
plot(g_true)
True DAG
Let’s first evaluate the true DAG on that data (the following cell will take approximately 20s to run)
[3]:
result = falsify_graph(g_true, data, plot_histogram=True)
# Summarize the result
print(result)
Test permutations of given graph: 100%|██████████| 20/20 [00:16<00:00, 1.20it/s]
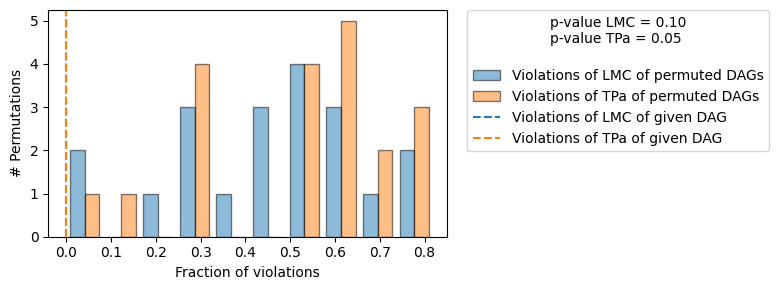
+-------------------------------------------------------------------------------------------------------+
| Falsificaton Summary |
+-------------------------------------------------------------------------------------------------------+
| The given DAG is informative because 1 / 20 of the permutations lie in the Markov |
| equivalence class of the given DAG (p-value: 0.05). |
| The given DAG violates 0/11 LMCs and is better than 90.0% of the permuted DAGs (p-value: 0.10). |
| Based on the provided significance level (0.05) and because the DAG is informative, |
| we do not reject the DAG. |
+-------------------------------------------------------------------------------------------------------+
As expected, we do not reject the true DAG. Let’s understand what falsify_graph() does exactly: When we provide a given DAG to falsify_graph(), we test violations of local Markov conditions (LMC) by running conditional independence tests (CIs). I.e. for each node in the graph we test if
We then randomly permute the nodes of the given DAG and test violations of LMC again. We can do this for either a fixed amount of permutations or for all \(n!,n:\) Number of nodes in the given DAG. We can then use the probability of a random node permutation (the null) having as few or fewer violations as the given DAG (the test statistic) as a measure to validate the given DAG (the p-value reported in the upper-right corner in the plot above).
Similarly, we can run an oracle test for each permutation w.r.t. the given DAG, i.e. if the given DAG were the true DAG, how many violations of LMCs do we expect for some permutation. Note, that asking about the number of permutations violating zero LMCs is identical to asking about how many DAGs lie in the same Markov equivalence class (MEC) as the given DAG. In our method we use the number of permuted DAGs lying in the same MEC as the given DAG (with 0 #Violations of tPA) as a measure of how informative the given DAG is. Only if few permutations lie in the same MEC, the independences entailed by the given DAG are ‘characteristic’ in the sense that the given DAG is falsifiable by testing implied CIs.
In the plot above we see histograms of the LMC violations of permuted DAGs (blue) and d-separation (oracle, orange) violations of the permuted DAGs. The dashed orange and blue line indicate the number of violations of LMC (blue) / d-separation (orange) of the given DAG. As expected for the true DAG, both histograms are broadly overlapping (except for statistical errors in the CI tests).
If we are not interested in the plot and just wish to know whether a given is falsified using our test we can use the falsified attribute of the returned EvaluationResult object of falsify_graph() instead.
[4]:
print(f"Graph is falsifiable: {result.falsifiable}, Graph is falsified: {result.falsified}")
Graph is falsifiable: True, Graph is falsified: False
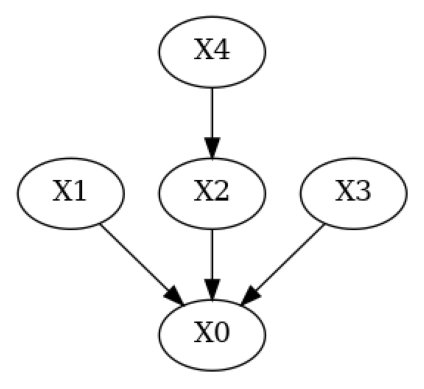
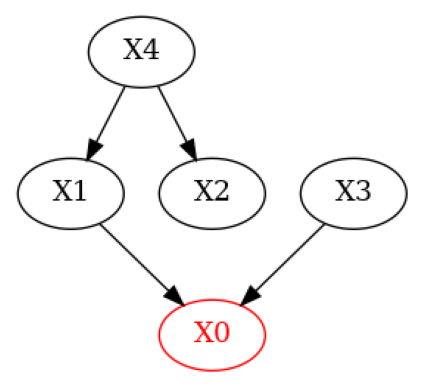
Now, let’s modify the true DAG to simulate a DAG where a domain expert knows some of the edges but removes a true one and introduces a wrong one.
[5]:
# Simulate a domain expert with knowledge over some of the edges in the system
g_given = g_true.copy()
g_given.add_edges_from(([('X4', 'X1')])) # Add wrong edge from X4 -> X1
g_given.remove_edge('X2', 'X0') # Remove true edge from X2 -> X0
plot(g_given)
[6]:
# Run evaluation and plot the result using `plot=True`
result = falsify_graph(g_given, data, plot_histogram=True)
# Summarize the result
print(result)
Test permutations of given graph: 100%|██████████| 20/20 [00:18<00:00, 1.11it/s]
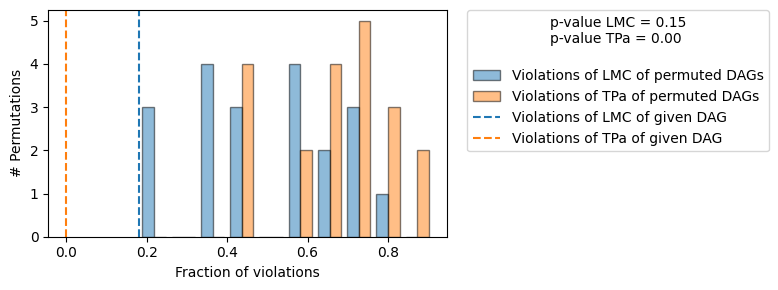
+-------------------------------------------------------------------------------------------------------+
| Falsificaton Summary |
+-------------------------------------------------------------------------------------------------------+
| The given DAG is informative because 0 / 20 of the permutations lie in the Markov |
| equivalence class of the given DAG (p-value: 0.00). |
| The given DAG violates 2/11 LMCs and is better than 85.0% of the permuted DAGs (p-value: 0.15). |
| Based on the provided significance level (0.05) and because the DAG is informative, |
| we reject the DAG. |
+-------------------------------------------------------------------------------------------------------+
Here, we observe two things. First, the given DAG violates 2 more LMCs than the true DAG. Second, there are many permuted DAGs that violate as many or less LMCs as the given DAG. This is reflected in the p-value LMC, which is much higher than before. Based on the default significance level of 0.05 we would therefore reject the given DAG.
We can gain additional insight by highlighting the nodes for which the violations of LMCs occurred in the given DAG.
[7]:
# Plot nodes for which violations of LMCs occured
print('Violations of LMCs')
plot_local_insights(g_given, result, method=FalsifyConst.VALIDATE_LMC)
Violations of LMCs
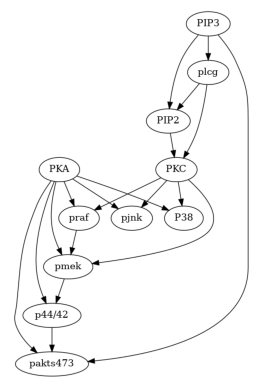
Real Data (Protein Network dataset by Sachs et al., 2005)
[8]:
# Load the data and consensus DAG
data_url = "https://raw.githubusercontent.com/FenTechSolutions/CausalDiscoveryToolbox/master/cdt/data/resources/cyto_full_data.csv"
data_sachs = pd.read_csv(data_url)
g_sachs = nx.read_gml('falsify_sachs.gml')
[9]:
plot(g_sachs)
Because of the large number of samples, evaluation using the kernel test above takes too long for this demo. Therefore, we’ll use a test based on the generalized covariance measure (GCM) instead. We’ll use sklearns gradient boosted decision trees as regressors.
[10]:
# Define independence test based on the generalised covariance measure with gradient boosted decision trees as models
def create_gradient_boost_regressor(**kwargs) -> SklearnRegressionModel:
return SklearnRegressionModel(GradientBoostingRegressor(**kwargs))
def gcm(X, Y, Z=None):
return generalised_cov_based(X, Y, Z=Z, prediction_model_X=create_gradient_boost_regressor,
prediction_model_Y=create_gradient_boost_regressor)
It is infeasible (and unnecessary) to run our baseline on all 11! node-permutations of the graph. We therefore set n_permutations=100 to evaluate using 100 random permutations. To use the GCM test defined above we’ll use the parameters independence_test=gcm (unconditional independence testing) and conditional_independence_test=gcm (conditional independence testing).
The following cell will take about 3min to run.
[11]:
# Run evaluation for consensus graph and data.
result_sachs = falsify_graph(g_sachs, data_sachs, n_permutations=100,
independence_test=gcm,
conditional_independence_test=gcm,
plot_histogram=True)
print(result_sachs)
Test permutations of given graph: 100%|██████████| 100/100 [11:09<00:00, 6.69s/it]
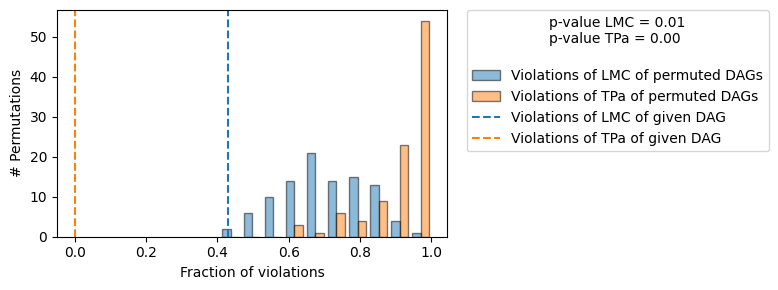
+-------------------------------------------------------------------------------------------------------+
| Falsificaton Summary |
+-------------------------------------------------------------------------------------------------------+
| The given DAG is informative because 0 / 100 of the permutations lie in the Markov |
| equivalence class of the given DAG (p-value: 0.00). |
| The given DAG violates 21/49 LMCs and is better than 99.0% of the permuted DAGs (p-value: 0.01). |
| Based on the provided significance level (0.05) and because the DAG is informative, |
| we do not reject the DAG. |
+-------------------------------------------------------------------------------------------------------+
We observe that the consensus DAG is both informative (0/100 permutations lie in the same MEC) and significantly better than random in terms of CI it entails. Note, that the number of LMC violations of the given DAG are much more than the expected type I error rate of the CI tests for the default significance level significance_ci=0.05 used here. The naive approach of rejecting a DAG with more than 5% violations of LMC would thus falsly reject this DAG.
Edge Suggestions
Beyond falsification of a given DAG shown above we can also run additional tests using suggestions=True and report those back to the user. To demonstrate this we will use the synthetic DAG and data from before.
[12]:
result = falsify_graph(g_given, data, plot_histogram=True, suggestions=True)
print(result)
Test permutations of given graph: 100%|██████████| 20/20 [00:18<00:00, 1.07it/s]
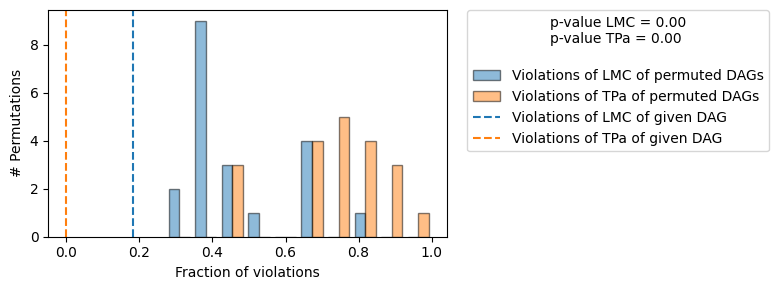
+-------------------------------------------------------------------------------------------------------+
| Falsificaton Summary |
+-------------------------------------------------------------------------------------------------------+
| The given DAG is informative because 0 / 20 of the permutations lie in the Markov |
| equivalence class of the given DAG (p-value: 0.00). |
| The given DAG violates 2/11 LMCs and is better than 100.0% of the permuted DAGs (p-value: 0.00). |
| Based on the provided significance level (0.05) and because the DAG is informative, |
| we do not reject the DAG. |
+-------------------------------------------------------------------------------------------------------+
| Suggestions |
+-------------------------------------------------------------------------------------------------------+
| Causal Minimality | - Remove edge X4 --> X1 |
+-------------------------------------------------------------------------------------------------------+
Compared to the output above we now see the additional row Suggestions in the print representation of the evaluation summary. We used a test of causal minimality to report suggestions to the user and would correctly suggest the removal of the edge \(X4 \to X1\), which was wrongly added by the domain expert. We can also plot those suggestions using plot_local_insights:
[13]:
# Plot suggestions
plot_local_insights(g_given, result, method=FalsifyConst.VALIDATE_CM)
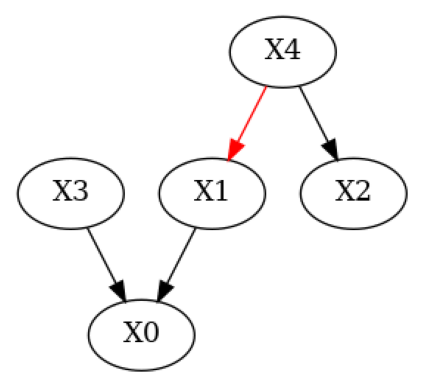
We can apply those suggestions using apply_suggestions. If there is an edge we do not want to remove we can use the additional parameter edges_to_keep to specify which edges we would not want to be removed.
[14]:
# Apply all suggestions (we could exclude suggestions via `edges_to_keep=[('X3', 'X4')])`)
g_given_pruned = apply_suggestions(g_given, result)
# Plot pruned DAG
plot(g_given_pruned)