Effect Estimation Using specific Effect Estimators (for ACE, mediation effect, …)#
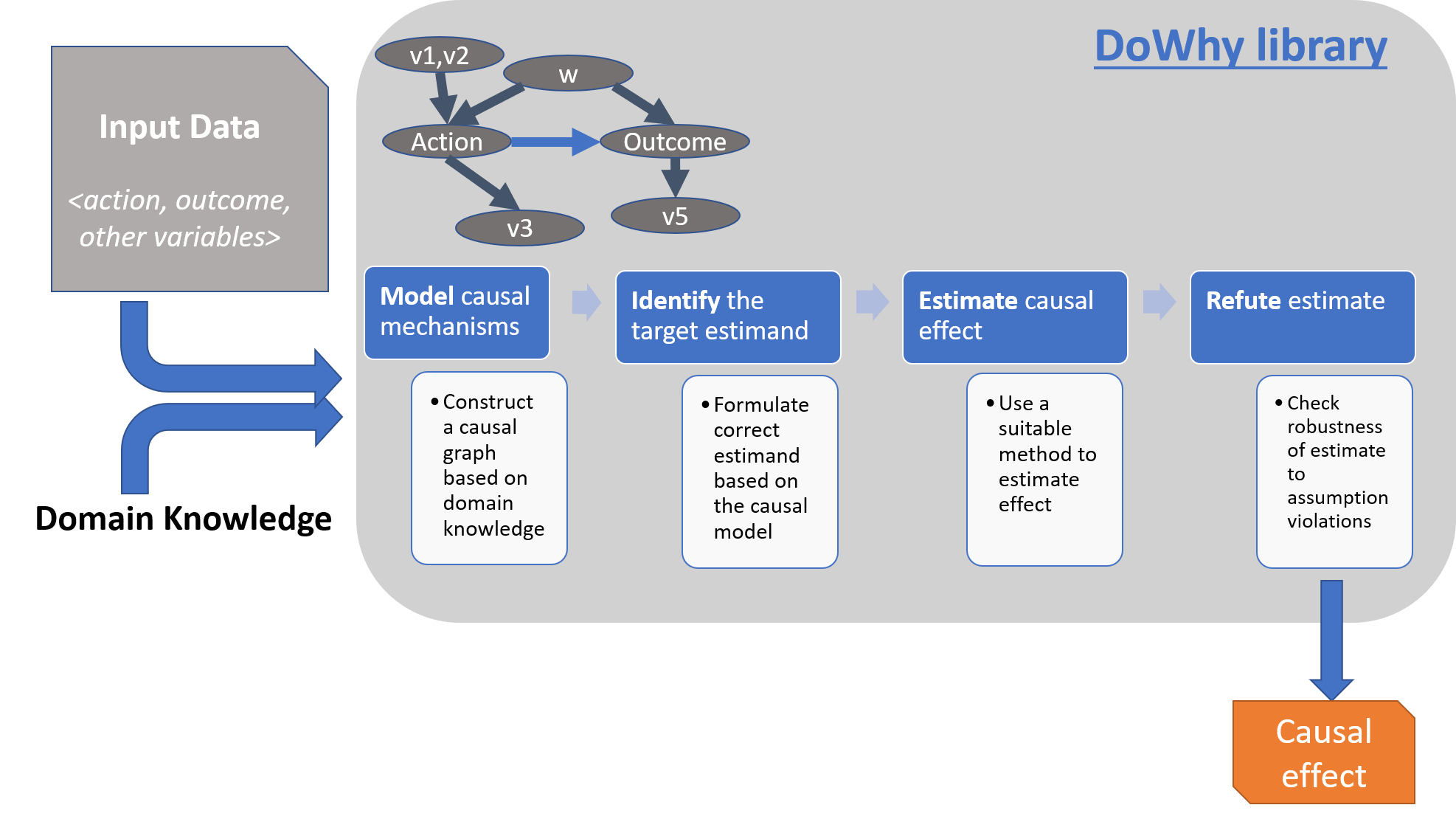
For effect estimation, DoWhy provides a principled four-step interface for causal inference that focuses on explicitly modeling causal assumptions and validating them as much as possible. The key feature of DoWhy is its state-of-the-art refutation API that can automatically test causal assumptions for any estimation method, thus making inference more robust and accessible to non-experts. DoWhy supports estimation of the average causal effect for backdoor, frontdoor, instrumental variable and other identification methods, and estimation of the conditional effect (CATE) through an integration with the EconML library.
Generating sample data and the causal model#
>>> from dowhy import CausalModel
>>> import dowhy.datasets
>>>
>>> # Load some sample data
>>> data = dowhy.datasets.linear_dataset(
>>> beta=10,
>>> num_common_causes=5,
>>> num_instruments=2,
>>> num_samples=10000,
>>> treatment_is_binary=True)
>>> model = CausalModel(
>>> data=data["df"],
>>> treatment=data["treatment_name"],
>>> outcome=data["outcome_name"],
>>> graph=data["gml_graph"])
Identify a target estimand under the model#
Based on the causal graph, DoWhy finds all possible ways of identifying a desired causal effect based on the graphical model. It uses graph-based criteria and do-calculus to find potential ways find expressions that can identify the causal effect.
>>> identified_estimand = model.identify_effect()
Supported identification criteria#
Back-door criterion
Front-door criterion
Instrumental Variables
Mediation (Direct and indirect effect identification)
Different notebooks illustrate how to use these identification criteria. Check out the Simple Backdoor notebook for the back-door criterion, and the Simple IV notebook for the instrumental variable criterion.
Estimate causal effect based on the identified estimand#
DoWhy supports methods based on both back-door criterion and instrumental variables. It also provides a non-parametric confidence intervals and a permutation test for testing the statistical significance of obtained estimate.
>>> estimate = model.estimate_effect(identified_estimand,
>>> method_name="backdoor.propensity_score_matching")
Supported estimation methods#
- Methods based on estimating the treatment assignment
Propensity-based Stratification
Propensity Score Matching
Inverse Propensity Weighting
- Methods based on estimating the outcome model
Linear Regression
Generalized Linear Models
- Methods based on the instrumental variable equation
Binary Instrument/Wald Estimator
Two-stage least squares
Regression discontinuity
- Methods for front-door criterion and general mediation
Two-stage linear regression
Examples of using these methods are in the Estimation methods notebook.
Using EconML and CausalML estimation methods in DoWhy#
It is easy to call external estimation methods using DoWhy. Currently we support integrations with the EconML and CausalML packages. Here’s an example of estimating conditional treatment effects using EconML’s double machine learning estimator.
from sklearn.preprocessing import PolynomialFeatures
from sklearn.linear_model import LassoCV
from sklearn.ensemble import GradientBoostingRegressor
dml_estimate = model.estimate_effect(identified_estimand, method_name="backdoor.econml.dml.DML",
control_value = 0,
treatment_value = 1,
target_units = lambda df: df["X0"]>1,
confidence_intervals=False,
method_params={
"init_params":{'model_y':GradientBoostingRegressor(),
'model_t': GradientBoostingRegressor(),
'model_final':LassoCV(),
'featurizer':PolynomialFeatures(degree=1, include_bias=True)},
"fit_params":{}}
)
More examples are in the Conditional Treatment Effects with DoWhy notebook.
Refute the obtained estimate#
Having access to multiple refutation methods to validate an effect estimate from a causal estimator is a key benefit of using DoWhy.
>>> refute_results = model.refute_estimate(identified_estimand, estimate,
>>> method_name="random_common_cause")
Supported refutation methods#
Add Random Common Cause: Does the estimation method change its estimate after we add an independent random variable as a common cause to the dataset? (Hint: It should not)
Placebo Treatment: What happens to the estimated causal effect when we replace the true treatment variable with an independent random variable? (Hint: the effect should go to zero)
Dummy Outcome: What happens to the estimated causal effect when we replace the true outcome variable with an independent random variable? (Hint: The effect should go to zero)
Simulated Outcome: What happens to the estimated causal effect when we replace the dataset with a simulated dataset based on a known data-generating process closest to the given dataset? (Hint: It should match the effect parameter from the data-generating process)
Add Unobserved Common Causes: How sensitive is the effect estimate when we add an additional common cause (confounder) to the dataset that is correlated with the treatment and the outcome? (Hint: It should not be too sensitive)
Data Subsets Validation: Does the estimated effect change significantly when we replace the given dataset with a randomly selected subset? (Hint: It should not)
Bootstrap Validation: Does the estimated effect change significantly when we replace the given dataset with bootstrapped samples from the same dataset? (Hint: It should not)
Examples of using refutation methods are in the Refutations notebook. For an advanced refutation that uses a simulated dataset based on user-provided or learnt data-generating processes, check out the Dummy Outcome Refuter notebook. As a practical example, this notebook shows an application of refutation methods on evaluating effect estimators for the Infant Health and Development Program (IHDP) and Lalonde datasets.
Comparison to other packages#
DoWhy’s effect inference API captures all four steps of causal inference:
Model a causal inference problem using assumptions.
Identify an expression for the causal effect under these assumptions (“causal estimand”).
Estimate the expression using statistical methods such as matching or instrumental variables.
Finally, verify the validity of the estimate using a variety of robustness checks.
This workflow is captured by four key verbs in DoWhy:
model
identify
estimate
refute
Using these verbs, DoWhy implements a causal inference engine that can support a variety of methods. model encodes prior knowledge as a formal causal graph, identify uses graph-based methods to identify the causal effect, estimate uses statistical methods for estimating the identified estimand, and finally refute tries to refute the obtained estimate by testing robustness to assumptions.
Key difference: Causal assumptions as first-class citizens#
Due to DoWhy’s focus on the full pipeline of causal analysis (not just a single step), there are three differences compared to available software for causal inference.
- Explicit identifying assumptions
Assumptions are first-class citizens in DoWhy.
Each analysis starts with a building a causal model. The assumptions can be viewed graphically or in terms of conditional independence statements. Wherever possible, DoWhy can also automatically test for stated assumptions using observed data.
- Separation between identification and estimation
Identification is the causal problem. Estimation is simply a statistical problem.
DoWhy respects this boundary and treats them separately. This focuses the causal inference effort on identification, and frees up estimation using any available statistical estimator for a target estimand. In addition, multiple estimation methods can be used for a single identified_estimand and vice-versa.
- Automated robustness checks
What happens when key identifying assumptions may not be satisfied?
The most critical, and often skipped, part of causal analysis is checking the robustness of an estimate to unverified assumptions. DoWhy makes it easy to automatically run sensitivity and robustness checks on the obtained estimate.
Finally, DoWhy is easily extensible, allowing other implementations of the four verbs to co-exist (e.g., we support implementations of the estimation verb from EconML and CausalML libraries). The four verbs are mutually independent, so their implementations can be combined in any way.