Time-decay Attribution and Causal Analysis#
The problem: Advertisers run campaigns across multiple channels (search, display, video) but struggle to know which ads actually drive sales. The standard approach, last-touch attribution (LTA), credits the final ad a customer saw before purchasing. This can systematically overcredit lower-funnel ads (search) that appear right before conversion, while undercrediting upper-funnel ads (display, video) that built awareness earlier. The result is misallocated budgets and underinvestment in channels with higher true ROI.
Two measurement approaches:
Time Decay Attribution (TDA): Reallocates LTA credit by modeling ad carryover, i.e., how impressions accumulate and decay over time. If upper-funnel ads have longer carryover, they gain credit in the time-decay approach vs LTA.
Causal Attribution (CA): Uses DoWhy to decompose YoY sales growth into ad-driven contributions. Thus we know how much each spend change contributed to business outcome.
These two approaches together tell you what types of ads influenced conversions beyond rule-based approaches and what drove growth.
[1]:
import dowhy
dowhy.enable_notebook_rendering()
import matplotlib.pyplot as plt
import networkx as nx
import numpy as np
import pandas as pd
from scipy import optimize
from sklearn.linear_model import Ridge
from sklearn.model_selection import TimeSeriesSplit
from sklearn.metrics import mean_absolute_error
import warnings
warnings.filterwarnings('ignore')
from dowhy import gcm
from dowhy.gcm.util import plot as plot_graph
from dowhy.gcm.falsify import falsify_graph, apply_suggestions
1. Data Generation#
Synthetic data with 4 ad channels: SP, SB, Display, Video:
SP/SB: high LTA share (75% combined), lower iROI ($2.20-2.50), fast decay
Display/Video: low LTA share (25%), higher iROI ($3.80-4.50), slow decay
[2]:
def generate_advertising_data(start_date='2024-01-01', end_date='2025-12-31', seed=0):
np.random.seed(seed)
dates = pd.date_range(start=start_date, end=end_date, freq='D')
n_days = len(dates)
day_of_year = np.array([d.dayofyear for d in dates])
year = np.array([d.year for d in dates])
day_of_week = np.array([d.dayofweek for d in dates])
# Seasonality: ±15% weekly, ±30% yearly (peaks ~June)
weekly_pattern = 1 + 0.15 * np.sin(2 * np.pi * day_of_week / 7)
yearly_pattern = 1 + 0.3 * np.sin(2 * np.pi * (day_of_year - 80) / 365)
yoy_growth = np.where(year == 2025, 1.08, 1.0) # 8% YoY growth
# Events: with year-over-year variation
special_shopping_event = np.zeros(n_days)
other_shopping_event = np.zeros(n_days)
for i, d in enumerate(dates):
# === SPECIAL SHOPPING EVENTS ===
# Prime Day
if d.year == 2024 and d.month == 7 and 16 <= d.day <= 17:
special_shopping_event[i] = 1
if d.year == 2025 and d.month == 7 and 8 <= d.day <= 9:
special_shopping_event[i] = 1
# Black Friday week
if d.year == 2024 and d.month == 11 and 25 <= d.day <= 30: # Thanksgiving Nov 28
special_shopping_event[i] = 1
if d.year == 2025 and d.month == 11 and 24 <= d.day <= 29: # Thanksgiving Nov 27
special_shopping_event[i] = 1
# Holiday shopping season
if d.month == 12 and d.day <= 24:
special_shopping_event[i] = 0.7
# Cyber Monday extended
if d.year == 2024 and d.month == 12 and 1 <= d.day <= 2:
special_shopping_event[i] = 1
if d.year == 2025 and d.month == 11 and d.day == 30:
special_shopping_event[i] = 1
# === OTHER SHOPPING EVENTS ===
# Valentine's Day
if d.month == 2 and 7 <= d.day <= 14:
other_shopping_event[i] = 1
# Easter
if d.year == 2024 and d.month == 3 and 25 <= d.day <= 31: # Easter Mar 31
other_shopping_event[i] = 1
if d.year == 2025 and d.month == 4 and 14 <= d.day <= 20: # Easter Apr 20
other_shopping_event[i] = 1
# Mother's Day week
if d.year == 2024 and d.month == 5 and 6 <= d.day <= 12: # May 12
other_shopping_event[i] = 1
if d.year == 2025 and d.month == 5 and 5 <= d.day <= 11: # May 11
other_shopping_event[i] = 1
# Memorial Day
if d.year == 2024 and d.month == 5 and 24 <= d.day <= 27:
other_shopping_event[i] = 1
if d.year == 2025 and d.month == 5 and 23 <= d.day <= 26:
other_shopping_event[i] = 1
# Father's Day week
if d.year == 2024 and d.month == 6 and 10 <= d.day <= 16: # Jun 16
other_shopping_event[i] = 1
if d.year == 2025 and d.month == 6 and 9 <= d.day <= 15: # Jun 15
other_shopping_event[i] = 1
# Back to school
if d.month == 8 and 1 <= d.day <= 31:
other_shopping_event[i] = 0.7
# Labor Day
if d.year == 2024 and d.month == 9 and 1 <= d.day <= 2:
other_shopping_event[i] = 1
if d.year == 2025 and d.month == 9 and 1 <= d.day <= 1:
other_shopping_event[i] = 1
# Halloween
if d.month == 10 and 20 <= d.day <= 31:
other_shopping_event[i] = 0.7
# Super Bowl week
if d.year == 2024 and d.month == 2 and 5 <= d.day <= 11: # Feb 11
other_shopping_event[i] = 1
if d.year == 2025 and d.month == 2 and 3 <= d.day <= 9: # Feb 9
other_shopping_event[i] = 1
# Spend: SP/SB track demand closely; Display/Video more stable for brand building
base_spend_sp = 15000 * yoy_growth * weekly_pattern * yearly_pattern
base_spend_sb = 8000 * yoy_growth * weekly_pattern * yearly_pattern
base_spend_display = 12000 * yoy_growth * weekly_pattern * (yearly_pattern ** 0.5)
base_spend_video = 6000 * yoy_growth * weekly_pattern * (yearly_pattern ** 0.3)
event_multiplier = 1 + 0.5 * special_shopping_event + 0.2 * other_shopping_event
# Noise: upper-funnel has more variance
sp_spend = base_spend_sp * event_multiplier * (1 + 0.15 * np.random.randn(n_days))
sb_spend = base_spend_sb * event_multiplier * (1 + 0.12 * np.random.randn(n_days))
display_spend = base_spend_display * event_multiplier * (1 + 0.18 * np.random.randn(n_days))
video_spend = base_spend_video * event_multiplier * (1 + 0.20 * np.random.randn(n_days))
sp_spend = np.maximum(sp_spend, 100)
sb_spend = np.maximum(sb_spend, 50)
display_spend = np.maximum(display_spend, 100)
video_spend = np.maximum(video_spend, 50)
# Impressions via CPM: SP=$2.50, SB=$3.00, Display=$1.50, Video=$8.00
sp_impressions = sp_spend / 2.5 * 1000
sb_impressions = sb_spend / 3.0 * 1000
display_impressions = display_spend / 1.5 * 1000
video_impressions = video_spend / 8.0 * 1000
# Ground truth: upper-funnel has higher iROI but gets less LTA credit
iroi_sp, iroi_sb, iroi_display, iroi_video = 2.5, 2.2, 3.8, 4.5
carryover_sp, carryover_sb, carryover_display, carryover_video = 0.3, 0.4, 0.7, 0.85
lta_rate_sp, lta_rate_sb, lta_rate_display, lta_rate_video = 0.45, 0.30, 0.18, 0.07
# Adstock: effective_spend[t] = spend[t] + carryover * effective_spend[t-1]
def apply_adstock(x, carryover):
adstocked = np.zeros_like(x)
adstocked[0] = x[0]
for t in range(1, len(x)):
adstocked[t] = x[t] + carryover * adstocked[t-1]
return adstocked
sp_adstocked = apply_adstock(sp_spend, carryover_sp)
sb_adstocked = apply_adstock(sb_spend, carryover_sb)
display_adstocked = apply_adstock(display_spend, carryover_display)
video_adstocked = apply_adstock(video_spend, carryover_video)
# Total sales = organic + (iROI × adstocked_spend) + event_lift + noise
organic_baseline = 80000 * yoy_growth * weekly_pattern * yearly_pattern
incremental_from_sp = iroi_sp * sp_adstocked
incremental_from_sb = iroi_sb * sb_adstocked
incremental_from_display = iroi_display * display_adstocked
incremental_from_video = iroi_video * video_adstocked
event_lift = 30000 * special_shopping_event + 10000 * other_shopping_event
total_sales = (organic_baseline +
incremental_from_sp + incremental_from_sb +
incremental_from_display + incremental_from_video +
event_lift + 5000 * np.random.randn(n_days))
total_sales = np.maximum(total_sales, 10000)
# LTA: 60% of sales are ad-touched, distributed by LTA contribution rates (independent of true iROI)
ad_touched_sales = 0.6 * total_sales * (1 + 0.1 * np.random.randn(n_days))
lta_sp = np.maximum(lta_rate_sp * ad_touched_sales * (1 + 0.08 * np.random.randn(n_days)), 0)
lta_sb = np.maximum(lta_rate_sb * ad_touched_sales * (1 + 0.10 * np.random.randn(n_days)), 0)
lta_display = np.maximum(lta_rate_display * ad_touched_sales * (1 + 0.12 * np.random.randn(n_days)), 0)
lta_video = np.maximum(lta_rate_video * ad_touched_sales * (1 + 0.15 * np.random.randn(n_days)), 0)
df = pd.DataFrame({
'activity_date': dates,
'year': year,
'quarter': [d.quarter for d in dates],
'month': [d.month for d in dates],
'day_of_week': day_of_week,
'sp_spend': sp_spend, 'sb_spend': sb_spend,
'display_spend': display_spend, 'video_spend': video_spend,
'sp_impressions': sp_impressions, 'sb_impressions': sb_impressions,
'display_impressions': display_impressions, 'video_impressions': video_impressions,
'special_shopping_event': special_shopping_event,
'other_shopping_event': other_shopping_event,
'total_sales': total_sales,
'ad_touched_sales': ad_touched_sales,
'lta_sales_sp': lta_sp, 'lta_sales_sb': lta_sb,
'lta_sales_display': lta_display, 'lta_sales_video': lta_video,
})
ground_truth = {
'iroi': {'SP': iroi_sp, 'SB': iroi_sb, 'Display': iroi_display, 'Video': iroi_video},
'carryover': {'SP': carryover_sp, 'SB': carryover_sb, 'Display': carryover_display, 'Video': carryover_video},
'lta_rate': {'SP': lta_rate_sp, 'SB': lta_rate_sb, 'Display': lta_rate_display, 'Video': lta_rate_video}
}
return df, ground_truth
df, ground_truth = generate_advertising_data()
print(f"Data: {len(df)} days, {df['activity_date'].min().date()} to {df['activity_date'].max().date()}")
print(f"Special event days: {(df['special_shopping_event'] > 0).sum()} ({(df['special_shopping_event'] > 0).mean()*100:.1f}%)")
print(f"Other event days: {(df['other_shopping_event'] > 0).sum()} ({(df['other_shopping_event'] > 0).mean()*100:.1f}%)")
df.head()
Data: 731 days, 2024-01-01 to 2025-12-31
Special event days: 65 (8.9%)
Other event days: 161 (22.0%)
[2]:
| activity_date | year | quarter | month | day_of_week | sp_spend | sb_spend | display_spend | video_spend | sp_impressions | ... | display_impressions | video_impressions | special_shopping_event | other_shopping_event | total_sales | ad_touched_sales | lta_sales_sp | lta_sales_sb | lta_sales_display | lta_sales_video | |
|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|
| 0 | 2024-01-01 | 2024 | 1 | 1 | 0 | 13404.441671 | 5099.747577 | 8952.575520 | 3858.257279 | 5.361777e+06 | ... | 5.968384e+06 | 482282.159891 | 0.0 | 0.0 | 155454.198911 | 87939.951886 | 37143.728760 | 23460.738849 | 13858.642324 | 6293.988387 |
| 1 | 2024-01-02 | 2024 | 1 | 1 | 1 | 12573.576417 | 5940.908870 | 10486.819125 | 5283.133227 | 5.029431e+06 | ... | 6.991213e+06 | 660391.653381 | 0.0 | 0.0 | 219463.068045 | 145232.875195 | 52965.494493 | 44159.286689 | 30375.435747 | 14314.282119 |
| 2 | 2024-01-03 | 2024 | 1 | 1 | 2 | 13979.535290 | 5680.663153 | 11816.388289 | 7530.793229 | 5.591814e+06 | ... | 7.877592e+06 | 941349.153615 | 0.0 | 0.0 | 284656.682628 | 172537.129670 | 76023.283438 | 46311.842059 | 27777.802951 | 9154.003839 |
| 3 | 2024-01-04 | 2024 | 1 | 1 | 3 | 15161.875157 | 7865.616003 | 9500.538566 | 5050.795393 | 6.064750e+06 | ... | 6.333692e+06 | 631349.424145 | 0.0 | 0.0 | 313792.139323 | 236249.947675 | 107409.255926 | 85420.610730 | 53827.211856 | 20315.500984 |
| 4 | 2024-01-05 | 2024 | 1 | 1 | 4 | 12775.945666 | 3888.599153 | 9579.377571 | 6822.546123 | 5.110378e+06 | ... | 6.386252e+06 | 852818.265345 | 0.0 | 0.0 | 323851.281693 | 185840.293859 | 75548.541173 | 61245.391132 | 32032.104714 | 8354.883341 |
5 rows × 21 columns
[3]:
print("Ground Truth:")
print(f" iROI: {ground_truth['iroi']}")
print(f" Carryover: {ground_truth['carryover']}")
print(f" LTA rates: {ground_truth['lta_rate']}")
Ground Truth:
iROI: {'SP': 2.5, 'SB': 2.2, 'Display': 3.8, 'Video': 4.5}
Carryover: {'SP': 0.3, 'SB': 0.4, 'Display': 0.7, 'Video': 0.85}
LTA rates: {'SP': 0.45, 'SB': 0.3, 'Display': 0.18, 'Video': 0.07}
[4]:
df_2024 = df[df['year'] == 2024]
df_2025 = df[df['year'] == 2025]
print(f"YoY Change (2025 vs 2024):")
for col in ['total_sales', 'sp_spend', 'sb_spend', 'display_spend', 'video_spend']:
pct = (df_2025[col].mean() - df_2024[col].mean()) / df_2024[col].mean() * 100
print(f" {col}: {pct:+.1f}%")
YoY Change (2025 vs 2024):
total_sales: +8.2%
sp_spend: +5.9%
sb_spend: +8.4%
display_spend: +7.9%
video_spend: +7.1%
2. Time Decay MTA#
Reallocate LTA credit using adstock transformation. Channels with higher carryover (Display/Video) accumulate more effective impressions over time, gaining credit vs LTA.
[5]:
def apply_adstock(series, carryover):
"""Geometric adstock: result[t] = x[t] + carryover * result[t-1]"""
result = np.zeros_like(series, dtype=float)
result[0] = series[0]
for t in range(1, len(series)):
result[t] = series[t] + carryover * result[t-1]
return result
def build_adstocked_features(X, carryover_map):
"""Apply channel-specific carryover to build adstocked feature matrix."""
X_adstocked = pd.DataFrame(index=X.index)
for col in X.columns:
carry = carryover_map.get(col, 0.5)
X_adstocked[col] = apply_adstock(X[col].values, carry)
return X_adstocked
def time_decay_attribution(X_adstocked, y, lam=10.0):
"""Ridge regression on adstocked features, rescaled to sum to total LTA."""
X_arr = X_adstocked.values
X_mean = X_arr.mean(axis=0)
X_std = X_arr.std(axis=0) + 1e-8
X_scaled = (X_arr - X_mean) / X_std
model = Ridge(alpha=lam, fit_intercept=True)
model.fit(X_scaled, y.values)
coefs = model.coef_ / X_std
y_pred = model.predict(X_scaled)
contributions = {}
for i, col in enumerate(X_adstocked.columns):
contrib = coefs[i] * X_adstocked[col].values
contributions[col] = np.maximum(contrib, 0).sum()
total_contrib = sum(contributions.values())
if total_contrib > 0:
scale = y.sum() / total_contrib
contributions = {k: v * scale for k, v in contributions.items()}
return contributions, model, y_pred
def cv_objective(params, X, y, channels, carryover_bounds, lambda_bounds, n_splits=5):
"""Cross-validation objective: validation MAE + overfitting penalty + regularization on carryover."""
n_channels = len(channels)
carryover_map = {channels[i]: params[i] for i in range(n_channels)}
lam = params[n_channels]
# Boundary check
for carry in carryover_map.values():
if carry < carryover_bounds[0] or carry > carryover_bounds[1]:
return 1e10
if lam < lambda_bounds[0] or lam > lambda_bounds[1]:
return 1e10
X_adstocked = build_adstocked_features(X, carryover_map)
tscv = TimeSeriesSplit(n_splits=n_splits)
train_maes, val_maes = [], []
for train_idx, val_idx in tscv.split(X_adstocked):
X_train, X_val = X_adstocked.iloc[train_idx], X_adstocked.iloc[val_idx]
y_train, y_val = y.iloc[train_idx], y.iloc[val_idx]
# Standardize using train stats only
X_train_arr = X_train.values
X_mean = X_train_arr.mean(axis=0)
X_std = X_train_arr.std(axis=0) + 1e-8
X_train_scaled = (X_train_arr - X_mean) / X_std
model = Ridge(alpha=lam, fit_intercept=True)
model.fit(X_train_scaled, y_train.values)
y_train_pred = model.predict(X_train_scaled)
X_val_scaled = (X_val.values - X_mean) / X_std
y_val_pred = model.predict(X_val_scaled)
train_maes.append(mean_absolute_error(y_train, y_train_pred))
val_maes.append(mean_absolute_error(y_val, y_val_pred))
train_mae = np.mean(train_maes)
val_mae = np.mean(val_maes)
gap_penalty = max(0, val_mae - train_mae) / (train_mae + 1e-8)
carryover_penalty = sum(c**2 for c in carryover_map.values()) / n_channels
return val_mae + 0.1 * gap_penalty * val_mae + 0.05 * carryover_penalty * val_mae
def optimize_carryover(X, y, channels, carryover_bounds=(0.1, 0.95), lambda_bounds=(1, 100), maxiter=50):
"""Find optimal carryover rates via differential evolution."""
n_channels = len(channels)
bounds = [carryover_bounds] * n_channels + [lambda_bounds]
result = optimize.differential_evolution(
cv_objective,
bounds=bounds,
args=(X, y, channels, carryover_bounds, lambda_bounds),
seed=0,
maxiter=maxiter,
tol=1e-6,
disp=False,
workers=1
)
carryover_map = {channels[i]: result.x[i] for i in range(n_channels)}
lam_opt = result.x[n_channels]
return carryover_map, lam_opt
[6]:
channels = ['SP', 'SB', 'Display', 'Video']
X_impressions = df.set_index('activity_date')[['sp_impressions', 'sb_impressions', 'display_impressions', 'video_impressions']].copy()
X_impressions.columns = channels
y_lta_total = df.set_index('activity_date')[['lta_sales_sp', 'lta_sales_sb', 'lta_sales_display', 'lta_sales_video']].sum(axis=1)
print(f"X: {X_impressions.shape}, y: {y_lta_total.shape}")
X: (731, 4), y: (731,)
[7]:
carryover_opt, lam_opt = optimize_carryover(
X_impressions, y_lta_total, channels,
carryover_bounds=(0.1, 0.95),
lambda_bounds=(5, 100),
maxiter=50
)
print("Optimized carryover rates:")
for ch, carry in carryover_opt.items():
half_life = np.log(0.5) / np.log(carry) if carry > 0 else 0
true_carry = ground_truth['carryover'].get(ch, 'N/A')
print(f" {ch}: {carry:.3f} (half-life: {half_life:.1f}d) | actual: {true_carry}")
print(f"Lambda: {lam_opt:.2f}")
Optimized carryover rates:
SP: 0.270 (half-life: 0.5d) | actual: 0.3
SB: 0.163 (half-life: 0.4d) | actual: 0.4
Display: 0.768 (half-life: 2.6d) | actual: 0.7
Video: 0.803 (half-life: 3.2d) | actual: 0.85
Lambda: 31.33
[8]:
X_adstocked = build_adstocked_features(X_impressions, carryover_opt)
mta_contrib, _, _ = time_decay_attribution(X_adstocked, y_lta_total, lam_opt)
lta_totals = {
'SP': df['lta_sales_sp'].sum(),
'SB': df['lta_sales_sb'].sum(),
'Display': df['lta_sales_display'].sum(),
'Video': df['lta_sales_video'].sum()
}
total_lta = sum(lta_totals.values())
total_mta = sum(mta_contrib.values())
[9]:
print("LTA vs MTA Attribution:")
print(f"{'Channel':<10} {'LTA ($M)':<12} {'LTA %':<10} {'MTA ($M)':<12} {'MTA %':<10} {'Shift':<10}")
print("-" * 64)
for ch in channels:
lta_val = lta_totals[ch] / 1e6
lta_pct = lta_totals[ch] / total_lta * 100
mta_val = mta_contrib[ch] / 1e6
mta_pct = mta_contrib[ch] / total_mta * 100
shift = mta_pct - lta_pct
print(f"{ch:<10} {lta_val:<12.1f} {lta_pct:<10.1f} {mta_val:<12.1f} {mta_pct:<10.1f} {shift:+.1f}pp")
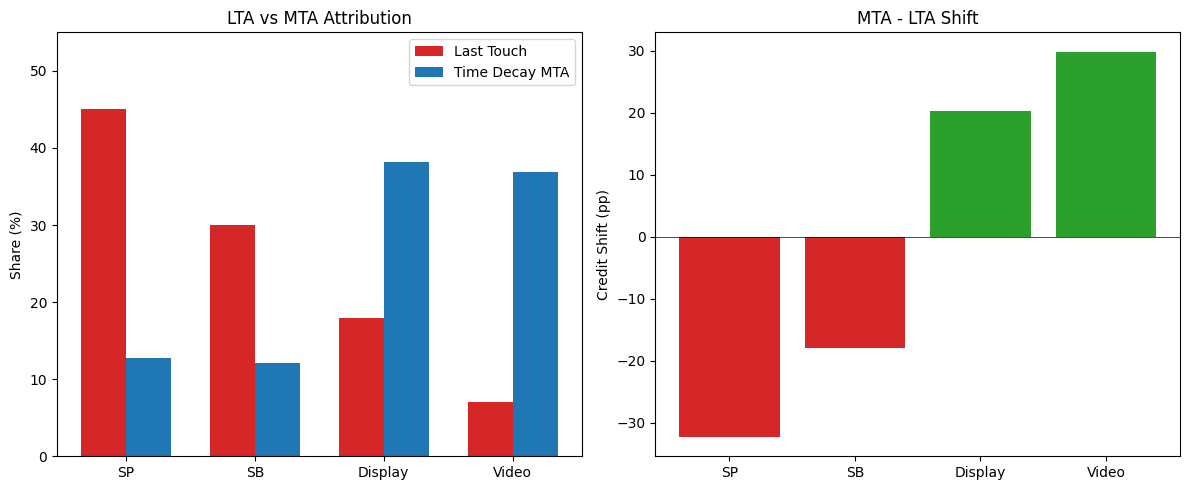
LTA vs MTA Attribution:
Channel LTA ($M) LTA % MTA ($M) MTA % Shift
----------------------------------------------------------------
SP 106.9 45.1 30.3 12.8 -32.3pp
SB 71.2 30.0 28.8 12.1 -17.9pp
Display 42.5 17.9 90.7 38.2 +20.3pp
Video 16.6 7.0 87.4 36.8 +29.8pp
[10]:
fig, axes = plt.subplots(1, 2, figsize=(12, 5))
x = np.arange(len(channels))
width = 0.35
ax1 = axes[0]
lta_pcts = [lta_totals[c]/total_lta*100 for c in channels]
mta_pcts = [mta_contrib[c]/total_mta*100 for c in channels]
ax1.bar(x - width/2, lta_pcts, width, label='Last Touch', color='tab:red')
ax1.bar(x + width/2, mta_pcts, width, label='Time Decay MTA', color='tab:blue')
ax1.set_xticks(x)
ax1.set_xticklabels(channels)
ax1.set_ylabel('Share (%)')
ax1.set_title('LTA vs MTA Attribution')
ax1.legend()
ax1.set_ylim(0, 55)
ax2 = axes[1]
shifts = [mta_pcts[i] - lta_pcts[i] for i in range(len(channels))]
colors = ['tab:green' if s > 0 else 'tab:red' for s in shifts]
ax2.bar(channels, shifts, color=colors)
ax2.axhline(y=0, color='black', linewidth=0.5)
ax2.set_ylabel('Credit Shift (pp)')
ax2.set_title('MTA - LTA Shift')
plt.tight_layout()
plt.show()
3. Causal Attribution (DoWhy)#
Decompose YoY sales growth into driver contributions using DoWhy GCM:
Build DAG: spend variables, other drivers → sale
Fit causal model
Attribute mean change via Shapley values
3.1 With Raw Spend#
This is the default approach by fitting the model directly on observed spend without any time-series transformation.
[11]:
df_causal = df[['activity_date', 'year', 'quarter',
'sp_spend', 'sb_spend', 'display_spend', 'video_spend',
'special_shopping_event', 'other_shopping_event',
'total_sales']].copy()
df_causal.columns = ['activity_date', 'year', 'quarter',
'sp_spend', 'sb_spend', 'display_spend', 'video_spend',
'special_shopping_event', 'other_shopping_event', 'sale']
print(f"Causal data: {len(df_causal)} rows")
Causal data: 731 rows
[12]:
# Build graph matching DGP structure
day_of_year = df['activity_date'].dt.dayofyear
df_causal['yearly_seasonality'] = 1 + 0.3 * np.sin(2 * np.pi * (day_of_year - 80) / 365)
df_causal['weekly_seasonality'] = 1 + 0.15 * np.sin(2 * np.pi * df['activity_date'].dt.dayofweek / 7)
edges = []
# Spend → sale
for col in ['sp_spend', 'sb_spend', 'display_spend', 'video_spend']:
edges.append((col, 'sale'))
# Seasonality → sale
edges.append(('yearly_seasonality', 'sale'))
edges.append(('weekly_seasonality', 'sale'))
# Seasonality → all spend
for col in ['sp_spend', 'sb_spend', 'display_spend', 'video_spend']:
edges.append(('yearly_seasonality', col))
edges.append(('weekly_seasonality', col))
# Events → sale
edges.append(('special_shopping_event', 'sale'))
edges.append(('other_shopping_event', 'sale'))
# Events → all spend
for col in ['sp_spend', 'sb_spend', 'display_spend', 'video_spend']:
edges.append(('special_shopping_event', col))
edges.append(('other_shopping_event', col))
causal_graph = nx.DiGraph(edges)
plot_graph(causal_graph)
[13]:
# Graph validation
RUN_GRAPH_VALIDATION = True
if RUN_GRAPH_VALIDATION:
validation_data = df_causal[['sp_spend','sb_spend','display_spend','video_spend',
'yearly_seasonality', 'weekly_seasonality','special_shopping_event', 'other_shopping_event','sale']]
result = falsify_graph(causal_graph, validation_data, suggestions=True, n_permutations=20)
print(result)
causal_graph = apply_suggestions(causal_graph, result)
print(f"\nRevised graph edges: {list(causal_graph.edges())}")
else:
print("Graph validation skipped")
Test permutations of given graph: 100%|██████████| 20/20 [00:20<00:00, 1.03s/it]
+-------------------------------------------------------------------------------------------------------+
| Falsification Summary |
+-------------------------------------------------------------------------------------------------------+
| The given DAG is informative because 0 / 20 of the permutations lie in the Markov |
| equivalence class of the given DAG (p-value: 0.00). |
| The given DAG violates 12/24 LMCs and is better than 100.0% of the permuted DAGs (p-value: 0.00). |
| Based on the provided significance level (0.05) and because the DAG is informative, |
| we do not reject the DAG. |
+-------------------------------------------------------------------------------------------------------+
| Suggestions |
+-------------------------------------------------------------------------------------------------------+
| Causal Minimality | - Remove edge weekly_seasonality --> sale |
+-------------------------------------------------------------------------------------------------------+
Revised graph edges: [('sp_spend', 'sale'), ('sb_spend', 'sale'), ('display_spend', 'sale'), ('video_spend', 'sale'), ('yearly_seasonality', 'sale'), ('yearly_seasonality', 'sp_spend'), ('yearly_seasonality', 'sb_spend'), ('yearly_seasonality', 'display_spend'), ('yearly_seasonality', 'video_spend'), ('weekly_seasonality', 'sp_spend'), ('weekly_seasonality', 'sb_spend'), ('weekly_seasonality', 'display_spend'), ('weekly_seasonality', 'video_spend'), ('special_shopping_event', 'sale'), ('special_shopping_event', 'sp_spend'), ('special_shopping_event', 'sb_spend'), ('special_shopping_event', 'display_spend'), ('special_shopping_event', 'video_spend'), ('other_shopping_event', 'sale'), ('other_shopping_event', 'sp_spend'), ('other_shopping_event', 'sb_spend'), ('other_shopping_event', 'display_spend'), ('other_shopping_event', 'video_spend')]
[14]:
causal_model = gcm.StructuralCausalModel(causal_graph)
gcm.auto.assign_causal_mechanisms(causal_model, df_causal, quality=gcm.auto.AssignmentQuality.BETTER)
gcm.fit(causal_model, df_causal)
Fitting causal mechanism of node other_shopping_event: 100%|██████████| 9/9 [00:00<00:00, 39.49it/s]
[15]:
# Define growth period for comparison
df_new = df_causal[(df_causal['year'] == 2025) & (df_causal['quarter'].isin([1, 2]))].copy()
df_old = df_causal[(df_causal['year'] == 2024) & (df_causal['quarter'].isin([1, 2]))].copy()
mean_old = df_old['sale'].mean()
mean_new = df_new['sale'].mean()
total_change = mean_new - mean_old
print(f"Comparing: 2025 H1 ({len(df_new)}d) vs 2024 H1 ({len(df_old)}d)")
print(f"Mean daily sales: 2024=${mean_old:,.0f}, 2025=${mean_new:,.0f}")
print(f"Daily change: ${total_change:,.0f}")
Comparing: 2025 H1 (181d) vs 2024 H1 (182d)
Mean daily sales: 2024=$512,443, 2025=$558,526
Daily change: $46,083
[16]:
# Decompose mean change via Shapley values
# Can swap np.mean for np.median or np.var to decompose those instead
median_contribs, uncertainty = gcm.confidence_intervals(
lambda: gcm.distribution_change(
causal_model, df_old, df_new, 'sale',
num_samples=2000,
difference_estimation_func=lambda x, y: np.mean(y) - np.mean(x)
),
confidence_level=0.95,
num_bootstrap_resamples=20
)
Evaluating set functions...: 100%|██████████| 154/154 [00:03<00:00, 42.91it/s]
Evaluating set functions...: 100%|██████████| 147/147 [00:03<00:00, 44.19it/s]
Evaluating set functions...: 100%|██████████| 149/149 [00:03<00:00, 44.66it/s]
Evaluating set functions...: 100%|██████████| 147/147 [00:03<00:00, 43.91it/s]
Evaluating set functions...: 100%|██████████| 156/156 [00:03<00:00, 43.60it/s]
Evaluating set functions...: 100%|██████████| 141/141 [00:03<00:00, 43.88it/s]
Evaluating set functions...: 100%|██████████| 148/148 [00:03<00:00, 42.19it/s]
Evaluating set functions...: 100%|██████████| 151/151 [00:03<00:00, 44.50it/s]
Evaluating set functions...: 100%|██████████| 154/154 [00:03<00:00, 43.60it/s]
Evaluating set functions...: 100%|██████████| 144/144 [00:03<00:00, 42.92it/s]
Evaluating set functions...: 100%|██████████| 148/148 [00:03<00:00, 44.14it/s]
Evaluating set functions...: 100%|██████████| 152/152 [00:03<00:00, 43.59it/s]
Evaluating set functions...: 100%|██████████| 143/143 [00:03<00:00, 45.13it/s]
Evaluating set functions...: 100%|██████████| 146/146 [00:03<00:00, 41.51it/s]
Evaluating set functions...: 100%|██████████| 145/145 [00:03<00:00, 42.06it/s]
Evaluating set functions...: 100%|██████████| 151/151 [00:03<00:00, 45.70it/s]
Evaluating set functions...: 100%|██████████| 148/148 [00:03<00:00, 43.58it/s]
Evaluating set functions...: 100%|██████████| 143/143 [00:03<00:00, 45.30it/s]
Evaluating set functions...: 100%|██████████| 146/146 [00:03<00:00, 38.41it/s]
Evaluating set functions...: 100%|██████████| 144/144 [00:03<00:00, 42.60it/s]
Estimating bootstrap interval...: 100%|██████████| 20/20 [01:30<00:00, 4.54s/it]
[17]:
growth_rate = (mean_new - mean_old) / mean_old * 100
print("Causal Attribution to YoY Sales Change:")
print(f"{'Driver':<20} {'Contrib $':<12} {'% of Total':<12} {'% of Growth':<12} {'iROAS':<10} {'95% CI':<22}")
print("-" * 98)
sum_contribs = 0
total_abs_contrib = sum(abs(v) for v in median_contribs.values())
spend_changes = {}
for col in ['sp_spend', 'sb_spend', 'display_spend', 'video_spend']:
spend_changes[col] = df_new[col].mean() - df_old[col].mean()
for node in sorted(median_contribs.keys(), key=lambda x: -abs(median_contribs[x])):
val = median_contribs[node]
sum_contribs += val
pct_total = (val / total_abs_contrib * 100) if total_abs_contrib > 0 else 0
pct_growth = (val / mean_old * 100)
lb, ub = uncertainty[node]
sig = "*" if (lb > 0 or ub < 0) else ""
if node in spend_changes:
spend_chg = spend_changes[node]
iroas = val / spend_chg if spend_chg != 0 else 0
print(f"{node:<20} ${val:>10,.0f} {pct_total:>10.1f}% {pct_growth:>10.2f}% ${iroas:>7.2f} {sig:<2} [{lb:>8,.0f}, {ub:>8,.0f}]")
else:
print(f"{node:<20} ${val:>10,.0f} {pct_total:>10.1f}% {pct_growth:>10.2f}% {'N/A':>8} {sig:<2} [{lb:>8,.0f}, {ub:>8,.0f}]")
print("-" * 98)
print(f"{'Sum of contributions':<20} ${sum_contribs:>10,.0f} {'':>11} {sum_contribs/mean_old*100:>10.2f}%")
print(f"{'Actual mean change':<20} ${total_change:>10,.0f} {'':>11} {growth_rate:>10.2f}%")
print(f"\nKPI summary (daily sales):")
print(f" 2024 H1: mean=${mean_old:,.0f}, median=${df_old['sale'].median():,.0f}")
print(f" 2025 H1: mean=${mean_new:,.0f}, median=${df_new['sale'].median():,.0f}")
print(f" YoY growth: {growth_rate:.2f}% (mean)")
print(f"\n* = CI excludes 0")
print(f"% of Growth = contribution / baseline mean")
print(f"iROAS = sales contribution / spend change")
print(f"'sale' row = unexplained variance (organic growth, noise)")
print(f"Note: Sum ≠ actual due to Monte Carlo sampling in Shapley estimation. Increase num_samples/num_bootstrap_resamples to reduce gap.")
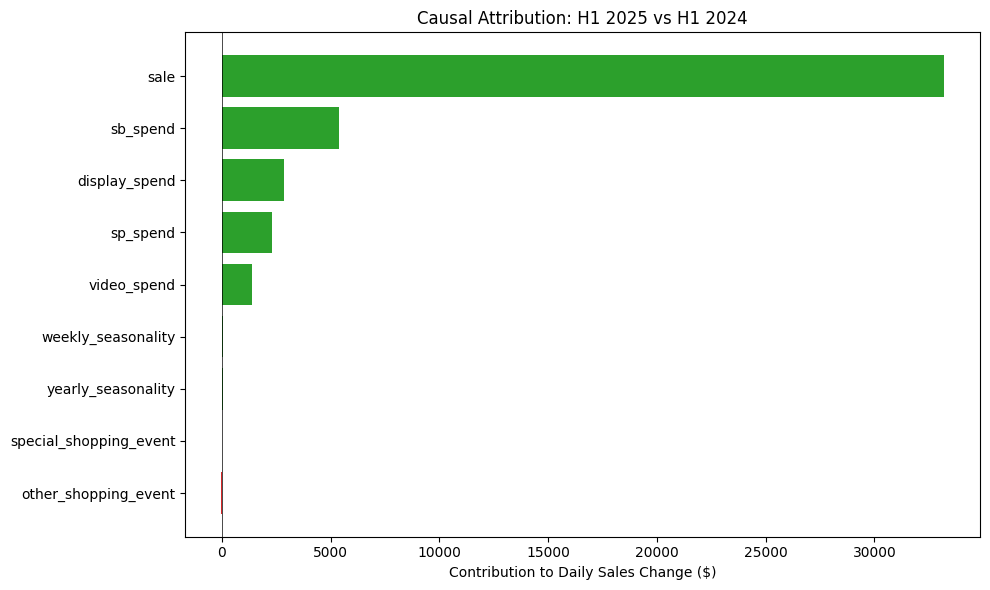
Causal Attribution to YoY Sales Change:
Driver Contrib $ % of Total % of Growth iROAS 95% CI
--------------------------------------------------------------------------------------------------
sale $ 33,194 73.3% 6.48% N/A * [ 32,110, 34,160]
sb_spend $ 5,374 11.9% 1.05% $ 5.89 * [ 4,410, 6,080]
display_spend $ 2,849 6.3% 0.56% $ 3.09 * [ 1,738, 3,867]
sp_spend $ 2,319 5.1% 0.45% $ 2.86 * [ 1,367, 3,318]
video_spend $ 1,398 3.1% 0.27% $ 2.85 * [ 673, 2,151]
weekly_seasonality $ 64 0.1% 0.01% N/A [ -890, 1,274]
yearly_seasonality $ 58 0.1% 0.01% N/A [ -1,183, 950]
special_shopping_event $ 24 0.1% 0.00% N/A [ -1,078, 1,310]
other_shopping_event $ -15 -0.0% -0.00% N/A [ -1,135, 608]
--------------------------------------------------------------------------------------------------
Sum of contributions $ 45,266 8.83%
Actual mean change $ 46,083 8.99%
KPI summary (daily sales):
2024 H1: mean=$512,443, median=$526,496
2025 H1: mean=$558,526, median=$556,330
YoY growth: 8.99% (mean)
* = CI excludes 0
% of Growth = contribution / baseline mean
iROAS = sales contribution / spend change
'sale' row = unexplained variance (organic growth, noise)
Note: Sum ≠ actual due to Monte Carlo sampling in Shapley estimation. Increase num_samples/num_bootstrap_resamples to reduce gap.
[18]:
fig, ax = plt.subplots(figsize=(10, 6))
drivers = list(median_contribs.keys())
contribs = [median_contribs[d] for d in drivers]
sorted_idx = np.argsort(contribs)[::-1]
drivers = [drivers[i] for i in sorted_idx]
contribs = [contribs[i] for i in sorted_idx]
colors = ['tab:green' if c > 0 else 'tab:red' for c in contribs]
ax.barh(drivers, contribs, color=colors)
ax.axvline(x=0, color='black', linewidth=0.5)
ax.set_xlabel('Contribution to Daily Sales Change ($)')
ax.set_title('Causal Attribution: H1 2025 vs H1 2024')
ax.invert_yaxis()
plt.tight_layout()
plt.show()
[19]:
print("iROI Estimation (via intervention):")
print(f"{'Channel':<15} {'Est. iROI':<15} {'Actual iROI':<15}")
print("-" * 45)
for spend_var, ch in [('sp_spend', 'SP'), ('sb_spend', 'SB'),
('display_spend', 'Display'), ('video_spend', 'Video')]:
step = 1000
effect = gcm.average_causal_effect(
causal_model=causal_model,
target_node='sale',
interventions_alternative={spend_var: lambda x, s=step: x + s},
interventions_reference={spend_var: lambda x: x},
num_samples_to_draw=10000
)
iroi = effect / step
actual_iroi = ground_truth['iroi'][ch]
print(f"{ch:<15} ${iroi:<14.2f} ${actual_iroi:<14.2f}")
iROI Estimation (via intervention):
Channel Est. iROI Actual iROI
---------------------------------------------
SP $2.09 $2.50
SB $8.42 $2.20
Display $3.96 $3.80
Video $4.14 $4.50
The iROI estimates differ from ground truth. Possible reasons:
DAG uses raw spend, but DGP applies adstock before computing sales
Auto-assigned mechanism may not capture the adstock transform
Unmeasured confounders (competitor activity, macro factors, etc.)
3.2 With Adstocked Spend#
Section 3.1 used raw spend as inputs, but our DGP generates sales from adstocked spend, where each day’s effect accumulates from prior days’ spending. This mismatch could explain the iROI gaps above.
To test this, we transform spend using ground truth carryover rates and refit:
[20]:
# Create adstocked spend columns using ground truth carryover rates
def apply_adstock(x, carryover):
adstocked = np.zeros_like(x)
adstocked[0] = x[0]
for t in range(1, len(x)):
adstocked[t] = x[t] + carryover * adstocked[t-1]
return adstocked
df_causal_adstocked = df_causal.copy()
df_causal_adstocked['sp_spend'] = apply_adstock(df_causal['sp_spend'].values, 0.3)
df_causal_adstocked['sb_spend'] = apply_adstock(df_causal['sb_spend'].values, 0.4)
df_causal_adstocked['display_spend'] = apply_adstock(df_causal['display_spend'].values, 0.7)
df_causal_adstocked['video_spend'] = apply_adstock(df_causal['video_spend'].values, 0.85)
# Rebuild causal model with adstocked data
causal_model_adstocked = gcm.StructuralCausalModel(causal_graph)
gcm.auto.assign_causal_mechanisms(causal_model_adstocked, df_causal_adstocked, quality=gcm.auto.AssignmentQuality.BETTER)
gcm.fit(causal_model_adstocked, df_causal_adstocked)
# Test iROI
print("iROI with adstocked spend:")
print(f"{'Channel':<15} {'Est. iROI':<15} {'Actual iROI':<15}")
print("-" * 45)
for spend_var, ch in [('sp_spend', 'SP'), ('sb_spend', 'SB'),
('display_spend', 'Display'), ('video_spend', 'Video')]:
step = 1000
effect = gcm.average_causal_effect(
causal_model=causal_model_adstocked,
target_node='sale',
interventions_alternative={spend_var: lambda x, s=step: x + s},
interventions_reference={spend_var: lambda x: x},
num_samples_to_draw=10000
)
iroi = effect / step
actual_iroi = ground_truth['iroi'][ch]
print(f"{ch:<15} ${iroi:<14.2f} ${actual_iroi:<14.2f}")
Fitting causal mechanism of node other_shopping_event: 100%|██████████| 9/9 [00:00<00:00, 39.24it/s]
iROI with adstocked spend:
Channel Est. iROI Actual iROI
---------------------------------------------
SP $2.58 $2.50
SB $5.62 $2.20
Display $3.95 $3.80
Video $3.40 $4.50
SP and SB improved drastically because these channels have correlated spend in the DGP, with both following demand seasonality and spike during events. We generated data that way to mimic real-world investment preferences.
When inputs are highly correlated, the model struggles to separate individual effects (that’s why SB showed bigger differences before because it was absorbing variance from other channels). Different carryover rates transform each channel differently, reducing correlation and letting the model distinguish their contributions.
In contrast, Display and Video were already close because their spend is more stable and less correlated with other channels (dampened seasonality in DGP). The model already works reasonably well without the transform.
Real data doesn’t come with known carryover rates, so this is more of a sanity check on the DGP than a practical approach.
4. Summary#
For reporting: LTA reflects what most attribution systems currently credits, MTA shows what credit would look like with carryover modeled, and causal attribution estimates actual business impact. When presenting to stakeholders, you can show all three to highlight the gap between LTA and MTA/causal highlights where budget reallocation opportunities exist.
[21]:
print("=" * 70)
print("Summary: LTA vs MTA vs Incrementality")
print("=" * 70)
print(f"{'Channel':<10} {'LTA %':<12} {'MTA %':<12} {'Shift':<12} {'Actual iROI':<12}")
print("-" * 58)
for ch in channels:
lta_pct = lta_totals[ch] / total_lta * 100
mta_pct = mta_contrib[ch] / total_mta * 100
shift = mta_pct - lta_pct
iroi = ground_truth['iroi'][ch]
print(f"{ch:<10} {lta_pct:<12.1f} {mta_pct:<12.1f} {shift:+11.1f}pp ${iroi:<11.2f}")
print("-" * 58)
print(f"\nSP+SB LTA share: {(lta_totals['SP']+lta_totals['SB'])/total_lta*100:.0f}%")
print(f"SP+SB MTA share: {(mta_contrib['SP']+mta_contrib['SB'])/total_mta*100:.0f}%")
print(f"Display+Video gain: {(mta_contrib['Display']+mta_contrib['Video'])/total_mta*100 - (lta_totals['Display']+lta_totals['Video'])/total_lta*100:+.0f}pp")
======================================================================
Summary: LTA vs MTA vs Incrementality
======================================================================
Channel LTA % MTA % Shift Actual iROI
----------------------------------------------------------
SP 45.1 12.8 -32.3pp $2.50
SB 30.0 12.1 -17.9pp $2.20
Display 17.9 38.2 +20.3pp $3.80
Video 7.0 36.8 +29.8pp $4.50
----------------------------------------------------------
SP+SB LTA share: 75%
SP+SB MTA share: 25%
Display+Video gain: +50pp